
How to Build Large Language Model Applications with PaLM API and LangChain


You can now use Generative AI Studio on Vertex AI to prompt, tune and deploy Google's foundational models, including PaLM 2, Imagen, Codey, and Chirp. You can easily design and fine-tune your prompt and copy the code required to deploy the solution.
Leveraging a foundational model is a no-brainer because of the time, complexity, and computational requirements for training these language models (LLMs) from scratch. Deploying large language applications through APIs, even open-source ones, is easier because the size of these models makes them harder to deploy.
There are numerous large language models; both closed and open-source. LangChain has become a popular solution for building LLMs applications because it reduces complexity and makes switching from one model to another easy.
In this article, you will discover how to use the PaLM API with LangChain to build LLM applications.
mlnuggets newsletter
Join the newsletter to receive the technical deep dives in your inbox.
Getting Started
You will learn how to use the PaLM API with two applications:
- Chatting with YouTube videos
- Chatting with PDFs
The first step is to install all the required libraries, including:
- LangChain
google-cloud-aiplatformpypdffor reading PDF files- Whisper for transcription
- Pytube for downloading YouTube videos
pip install google-cloud-aiplatform google-api-python-client pypdf langchain pytube git+https://github.com/openai/whisper.gitYou can follow along using this and this Kaggle notebook.
Chat With YouTube Video
Chatting with YouTube videos is done in the following steps:
- Download the video using PyTube
- Convert the video to audio
- Transcribe the video using Whisper
- Split the transcribed text into chunks because the LLMs have a maximum number of tokens they can accept
- Create word embeddings for each chunk
- Store the embeddings in a vector database
- Create an embedding for the question
- Compare the questions embedding's to the embeddings in the vector store
- Return the top similar embeddings
- Pass these embeddings instead of the entire text to the LLM
- Get a response from the LLM
Let's look at the code implementation. First, import all the required packages:
import pandas as pd
# Utils
import time
from typing import List
from pydantic import BaseModel
from google.cloud import aiplatform
from langchain.chat_models import ChatVertexAI
from langchain.embeddings import VertexAIEmbeddings
from langchain.llms import VertexAI
from langchain.vectorstores import Chroma
from langchain.document_loaders.csv_loader import CSVLoader
from langchain.vectorstores import Chroma
import whisper
from pytube import YouTube
from langchain.chains import RetrievalQA
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
Authenticate Your Google Cloud Account
Using the PaLM API requires that you authenticate your Google account:
import vertexai
PROJECT_ID = "PROJECT_ID" # @param {type:"string"}
vertexai.init(project=PROJECT_ID, location="us-central1")Transcribe Video
Next, use PyTube to download the video and Whisper to transcribe it. Save the result in a CSV file.
YOUTUBE_VIDEOS = ["https://www.youtube.com/watch?v=Ibjm2KHfymo"]
def transcribe(youtube_url, model):
youtube = YouTube(youtube_url)
audio = youtube.streams.filter(only_audio=True).first()
with tempfile.TemporaryDirectory() as tmpdir:
file = audio.download(output_path=tmpdir)
title = os.path.basename(file)[:-4]
result = model.transcribe(file, fp16=False)
return title, youtube_url, result["text"].strip()
transcriptions = []
model = whisper.load_model("base")
for youtube_url in YOUTUBE_VIDEOS:
transcriptions.append(transcribe(youtube_url, model))
df = pd.DataFrame(transcriptions, columns=["title", "url", "text"])
df.to_csv("text.csv")
mlnuggets newsletter
Join the newsletter to receive the technical deep dives in your inbox.
Load Transcribe Text With LangChain
LangChain provides various data loaders. In this case, we are interested in the CSVLoader.
file = "text.csv"
loader = CSVLoader(file_path=file)
docs = loader.load()Set Up Vertex AI Embeddings
The following is a utility function for using the Vertex AI Embedding with rate limiting. Check the Console Quoatas page for the allowed request per minute.
# Utility functions for Embeddings API with rate limiting
def rate_limit(max_per_minute):
period = 60 / max_per_minute
print("Waiting")
while True:
before = time.time()
yield
after = time.time()
elapsed = after - before
sleep_time = max(0, period - elapsed)
if sleep_time > 0:
print(".", end="")
time.sleep(sleep_time)
class CustomVertexAIEmbeddings(VertexAIEmbeddings, BaseModel):
requests_per_minute: int
num_instances_per_batch: int
# Overriding embed_documents method
def embed_documents(self, texts: List[str]):
limiter = rate_limit(self.requests_per_minute)
results = []
docs = list(texts)
while docs:
# Working in batches because the API accepts maximum 5
# documents per request to get embeddings
head, docs = (
docs[: self.num_instances_per_batch],
docs[self.num_instances_per_batch :],
)
chunk = self.client.get_embeddings(head)
results.extend(chunk)
next(limiter)
return [r.values for r in results]
# Embedding
EMBEDDING_QPM = 100
EMBEDDING_NUM_BATCH = 5
embeddings = CustomVertexAIEmbeddings(
requests_per_minute=EMBEDDING_QPM,
num_instances_per_batch=EMBEDDING_NUM_BATCH,
)Store the Text Embeddings in a Vector Database
There are various open-source vector databases for storing word embeddings. Chromadb is a common choice among developers.
Next, set up a retriever to fetch documents and pass them to the LLM.
db = Chroma.from_documents(docs, embeddings)
retriever = db.as_retriever()Answering Questions from the YouTube Video
To answer questions from the video, you need to set up the VertexAI LLM and the RetrievalQA from LangChain.
llm = VertexAI(
model_name="text-bison@001",
max_output_tokens=256,
temperature=0,
top_p=0.8,
top_k=40,
verbose=True,
)
qa_stuff = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
verbose=True
)
query = "WHow is Java mounting a come back?"
response = qa_stuff.run(query)
"""Java is mounting a comeback because it is a well-balanced language that is performing enough for most things. It is relatively easy to use, and most importantly, has a huge ecosystem of stable libraries and frameworks."""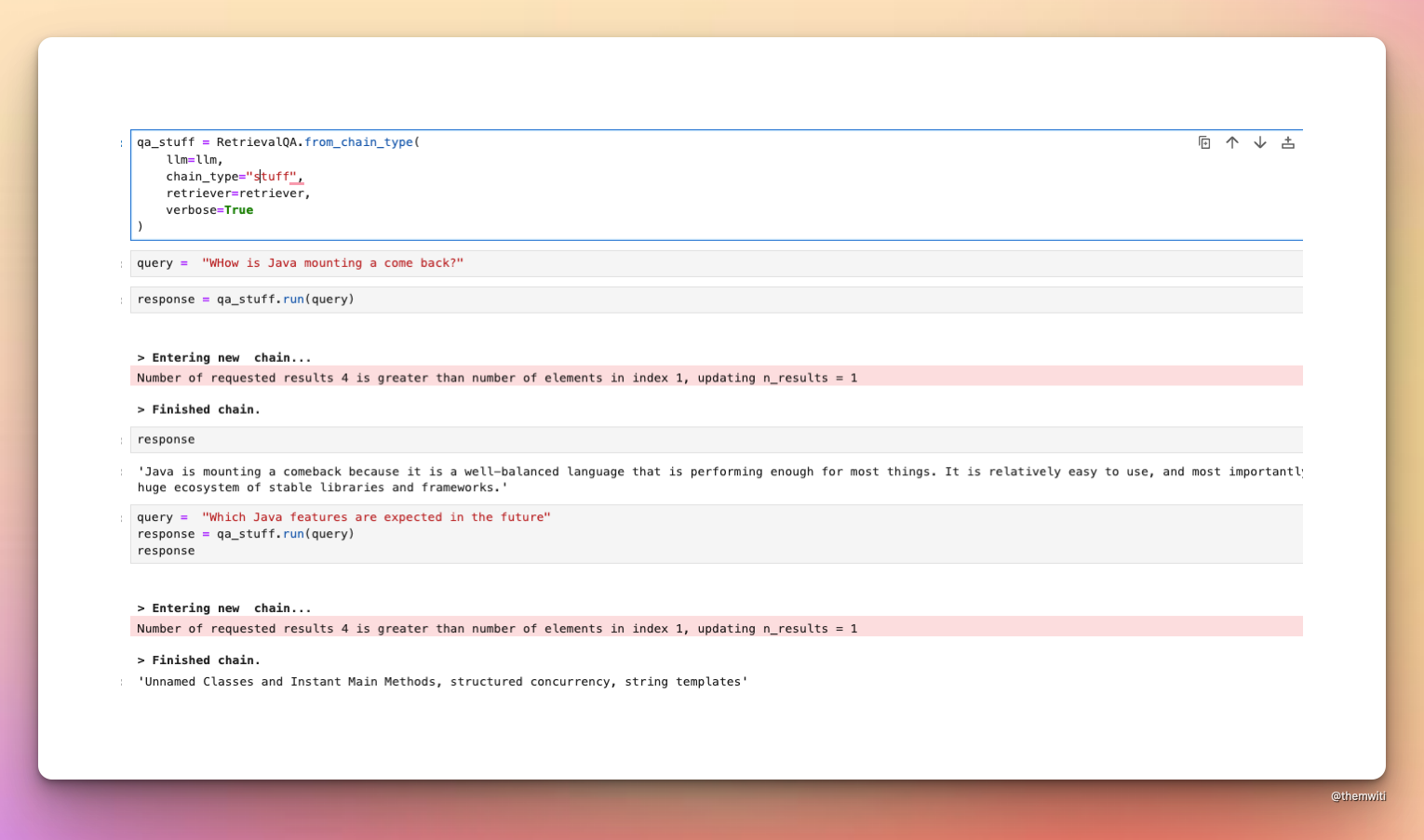
mlnuggets newsletter
Join the newsletter to receive the technical deep dives in your inbox.
Chat With PDFs
The process of chatting with PDFs is very similar to the video application. The only difference is reading in the PDF with LangChain.
Load PDF With LangChain
LangChain provides various utilities for loading a PDF. Let's use the PyPDFLoader.
loader = PyPDFLoader("yourpdf.pdf")
documents = loader.load()
Split the Text Into Chunks
We used a very short video from the Fireship YouTube channel in the video example. However, in some cases, the text will be too long to fit the LLM's context. In such a case, you have to split it into chunks. LangChain provides tools for doing that.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
texts = text_splitter.split_documents(documents)Save the Embeddings of the PDF Text
Save the text embeddings using Chromadb as done previously.
db = Chroma.from_documents(texts, embeddings)
retriever = db.as_retriever()Question Answering With the PDF Text
Next, use ChatVertexAI and start chatting with the PDF.
llm = ChatVertexAI()
qa_stuff = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
verbose=True
)
In this case, let's have the LLM summarize the contents of the PDF as a list.
from langchain.schema import (
HumanMessage
)
# prepare template for prompt
template = """You are an advanced AI assistant that summarizes online articles into bulleted lists.
Here's the article you need to summarize.
==================
Title: {article_title}
{article_text}
==================
Now, provide a summarized version of the article in a bulleted list format.
"""
# format prompt
prompt = template.format(article_title="Activation functions in JAX and Flax", article_text="texts")
# generate summary
summary = llm([HumanMessage(content=prompt)])
print(summary.content)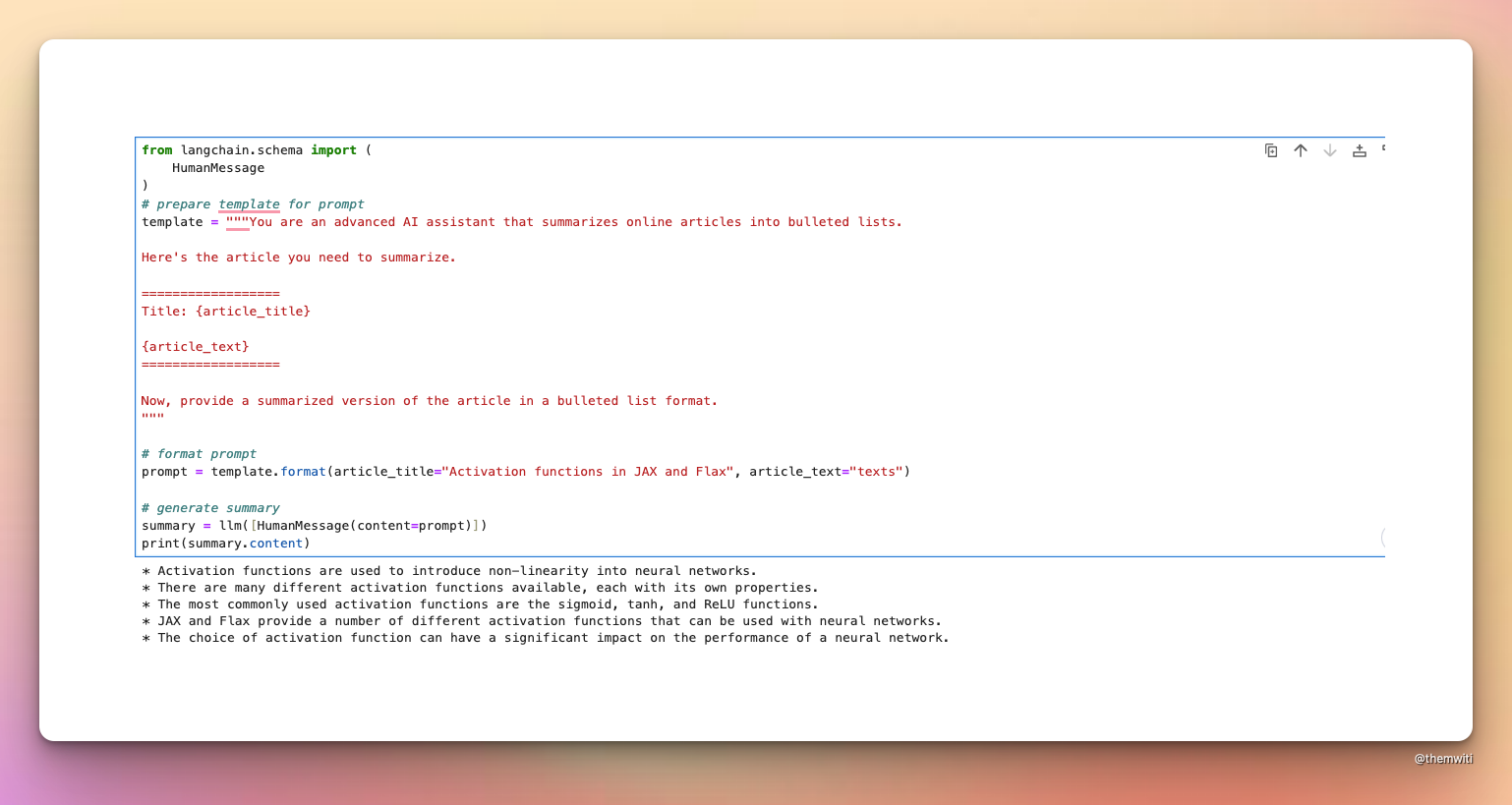
As you can see from the screenshot, the model summarized the PDF in a list format as instructed.
mlnuggets newsletter
Join the newsletter to receive the technical deep dives in your inbox.
Final Thoughts
These two applications provide a glimpse into the world of building applications using Google's foundational models. What you build using them is only limited by your imagination. What will you build? Let me know in the comments below or by replying to this email.
Whenever you're ready, there is 2 way I can help you:
If you're looking to accelerate your career, I'd recommend starting with an affordable ebook:
→ Writing for Data Scientists: The exact path I followed to get technical work that pays between $250-$500 from machine learning companies such as Comet, Neptune, cnvrg, Paperspace, Layer, Neural Magic, Determined, Activeloop, and many more. Get your copy.
→ Data Science and Machine Learning Ebook: I offer numerous free and paid data science and machine learning ebooks to help you in your data science and machine learning career. Check them out.