
How to Detect AI Generated Content With TensorFlow


With the plethora of open-source language models, it's incredibly difficult to determine if a piece of text is AI generated. However, with a good dataset, you can train a model in TensorFlow to detect if a large language model generated text. It's such an interesting problem that there is even a Kaggle competition dedicated to solving it.
In this blog post, we'll take a stab at solving this problem using TensorFlow.
Getting Started
We kick off by importing all the required modules:
- Pandas to load the dataset
arrayto convert the text to NumPy arrays- Matplotlib to plot the test and validation chats
- TensorFlow utilities for building the network
from numpy import array
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, LSTM, BidirectionalLoad the Data
To train the model, we use the DAIGT V2 Train Dataset. Load the dataset with Pandas and drop any duplicates in the dataset.
test = pd.read_csv('/kaggle/input/llm-detect-ai-generated-text/test_essays.csv')
sub = pd.read_csv('/kaggle/input/llm-detect-ai-generated-text/sample_submission.csv')
org_train = pd.read_csv('/kaggle/input/llm-detect-ai-generated-text/train_essays.csv')
train = pd.read_csv("/kaggle/input/daigt-v2-train-dataset/train_v2_drcat_02.csv", sep=',')
train = train.drop_duplicates(subset=['text'])Display part of the training set:
train.head()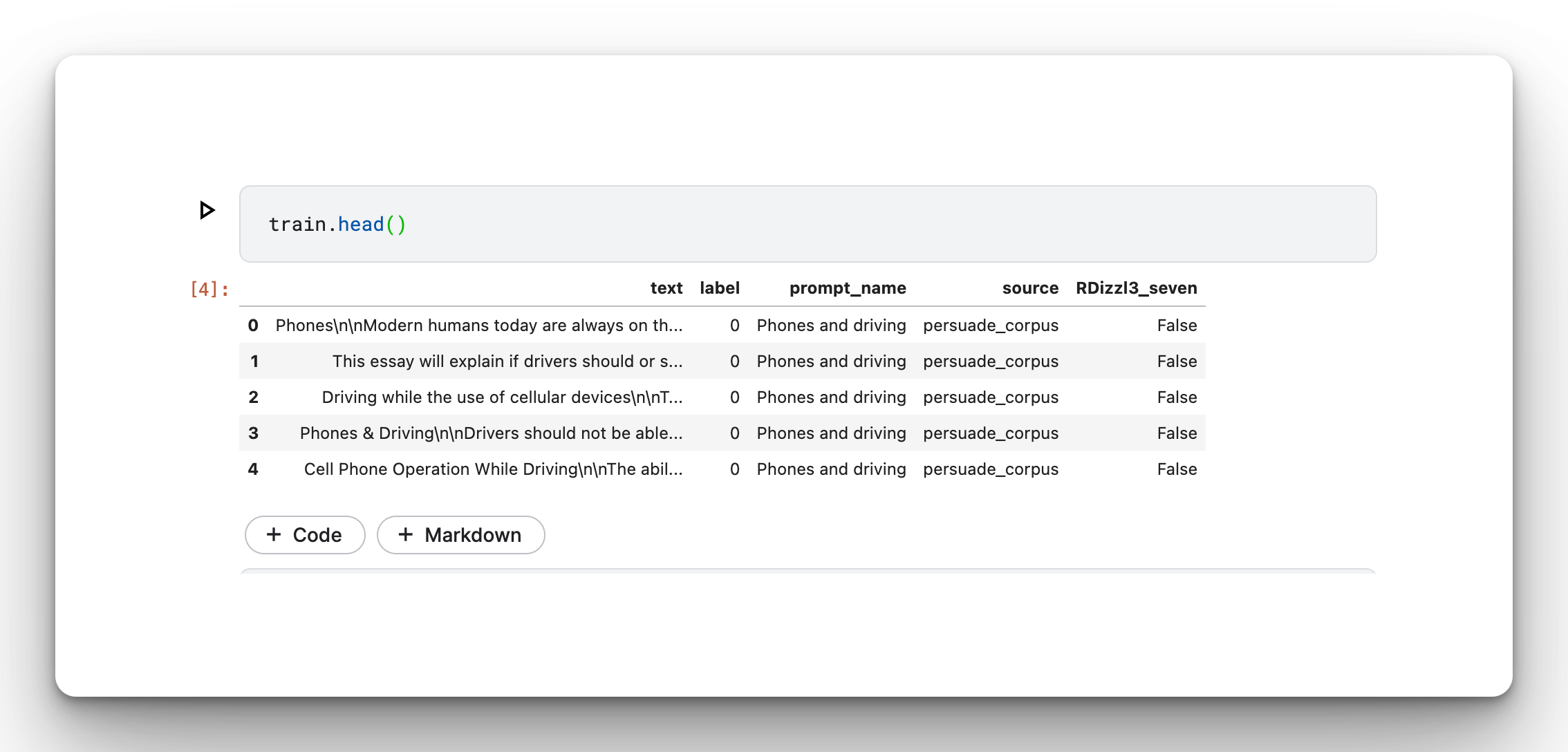
For this exercise, we are interested in the text and label columns.
Split the Data
Next, split the data into a training and validation set using Scikit-learn. We'll use 80% for training and 20% for validation.
docs = train['text']
labels = array(train['label'])
X_train, X_test , y_train, y_test = train_test_split(docs, labels , test_size = 0.2, random_state=0)
Text Vectorization in TensorFlow
Deep learning models don't understand raw text. We, therefore, have to convert the text to a numerical representation. In TensorFlow, this is done using the TextVectorization layer. Given text, the layer will create a sequence of integers. Some of the arguments you can pass to the layer are:
standardizeto apply specific standardizations to the text, for example,lower_and_strip_punctuationwill lowercase all the text and remove punctuation.max_tokensto determine the vocabulary size.output_modedictates the output of the layer, for example,intwill output integers.output_sequence_lengthensure that the text is padded or truncated to the maximum sequence length
max_features = 150000 # Maximum vocab size.
batch_size = 32
max_len = 300 # Sequence length to pad the outputs to.
vectorize_layer = tf.keras.layers.TextVectorization(standardize='lower_and_strip_punctuation',
max_tokens=max_features,
output_mode='int',
output_sequence_length=max_len)
vectorize_layer.adapt(X_train,batch_size=None)
vocab_size = vectorize_layer.vocabulary_size()
X_train_padded = vectorize_layer(X_train)
X_test_padded = vectorize_layer(X_test)
test_data = vectorize_layer(test['text'])Create TensorFlow Dataset
Next, create a TensorFlow dataset and create batches. Setting up a TensorFlow dataset allows you to configure further data settings such as prefetching the data with an automatic buffer size.
training_data = tf.data.Dataset.from_tensor_slices((X_train_padded, y_train))
validation_data = tf.data.Dataset.from_tensor_slices((X_test_padded, y_test))
training_data = training_data.batch(batch_size)
validation_data = validation_data.batch(batch_size)Setup Pretrained Word Embeddings
A word embedding is a representation of text data in a vector space such that similar words appear close to each other. In this case, words that are more likely to be generated by an LLM may be close to each other. In TensorFlow, we can use the Embedding layer to achieve that. You can either train one from scratch or use a pre-trained one. In this case, we will do the latter.
We will use the pre-trained GloVe embeddings to initialize a pretrained Embedding layer. The process involves loading the embeddings into an embeddings_index dictionary.
embeddings_index = {}
f = open('/kaggle/input/glove7b/glove.6B.300d.txt')
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Found %s word vectors.' % len(embeddings_index))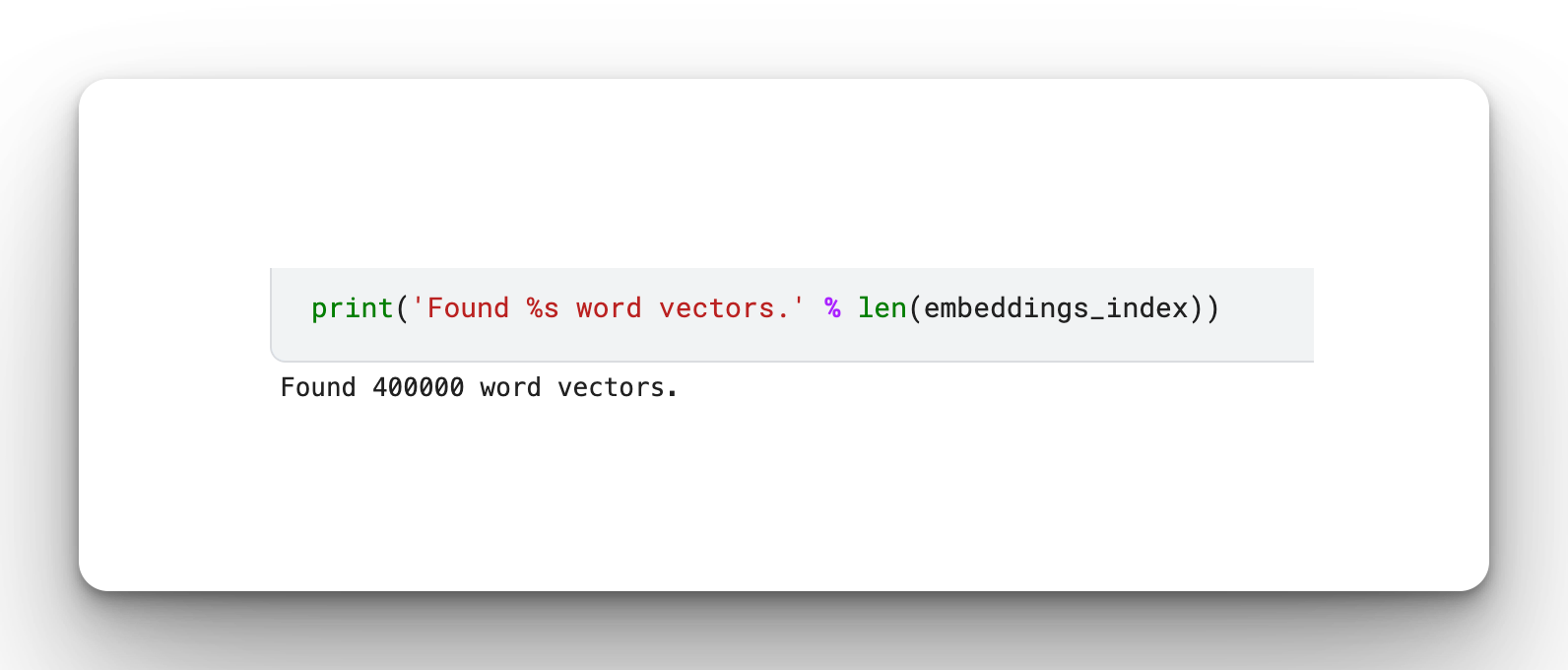
For example, here is part of the vector representation of the word word:
The next step is to create an embedding matrix by looking at every word in our vocabulary and fetching its embedding matrix from the embeddings_index dictionary. If a word can't be found it will be represented by zeros.
vocabulary=vectorize_layer.get_vocabulary()
embedding_matrix = np.zeros((len(vocabulary) + 1, max_len))
for i,word in enumerate(vocabulary):
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
# words not found in embedding index will be all-zeros.
embedding_matrix[i] = embedding_vectorCreate TensorFlow Model
To create the network, we start by creating an embedding layer from the computed embedding matrix. We do this by initializing the Embedding layer and setting the weights to the embedding matrix. Setting trainable to False ensures that the layer is not trained again.
input_dim is set asvocab_size + 1 representing the size of the vocabulary. The second argument, output_dim is the dimension of the dense embedding. input_length is the length of the input sequences.
embedding_layer = Embedding(vocab_size + 1,
max_len,
weights=[embedding_matrix],
input_length=max_len,
trainable=False)
Define the model using the Keras Sequential layer:
model = Sequential([
embedding_layer,
Bidirectional(LSTM(256, return_sequences=True)),
Bidirectional(LSTM(128, return_sequences=True)),
Bidirectional(LSTM(64, return_sequences=True)),
Bidirectional(LSTM(32,)),
Dense(300, activation='relu'),
Dense(150, activation='relu'),
Dense(75, activation='relu'),
Dense(24, activation='relu'),
Dense(1, activation='sigmoid')
])
The network uses a bidirectional LSTM to ensure that information flows in both directions. Since it's a binary classification problem, the final output has 1 unit and the sigmoid activation fiction.
Train TensorFlow Model
Compile and train the model:
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
num_epochs = 20
history = model.fit(training_data, epochs=num_epochs, validation_data=validation_data)
Plot Model Evaluation Charts
When training is complete, we can plot the training and validation charts using Matplotlib:
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper left')
plt.show()Finally, you can run predictions on the test set.
final_preds = model.predict(test_data)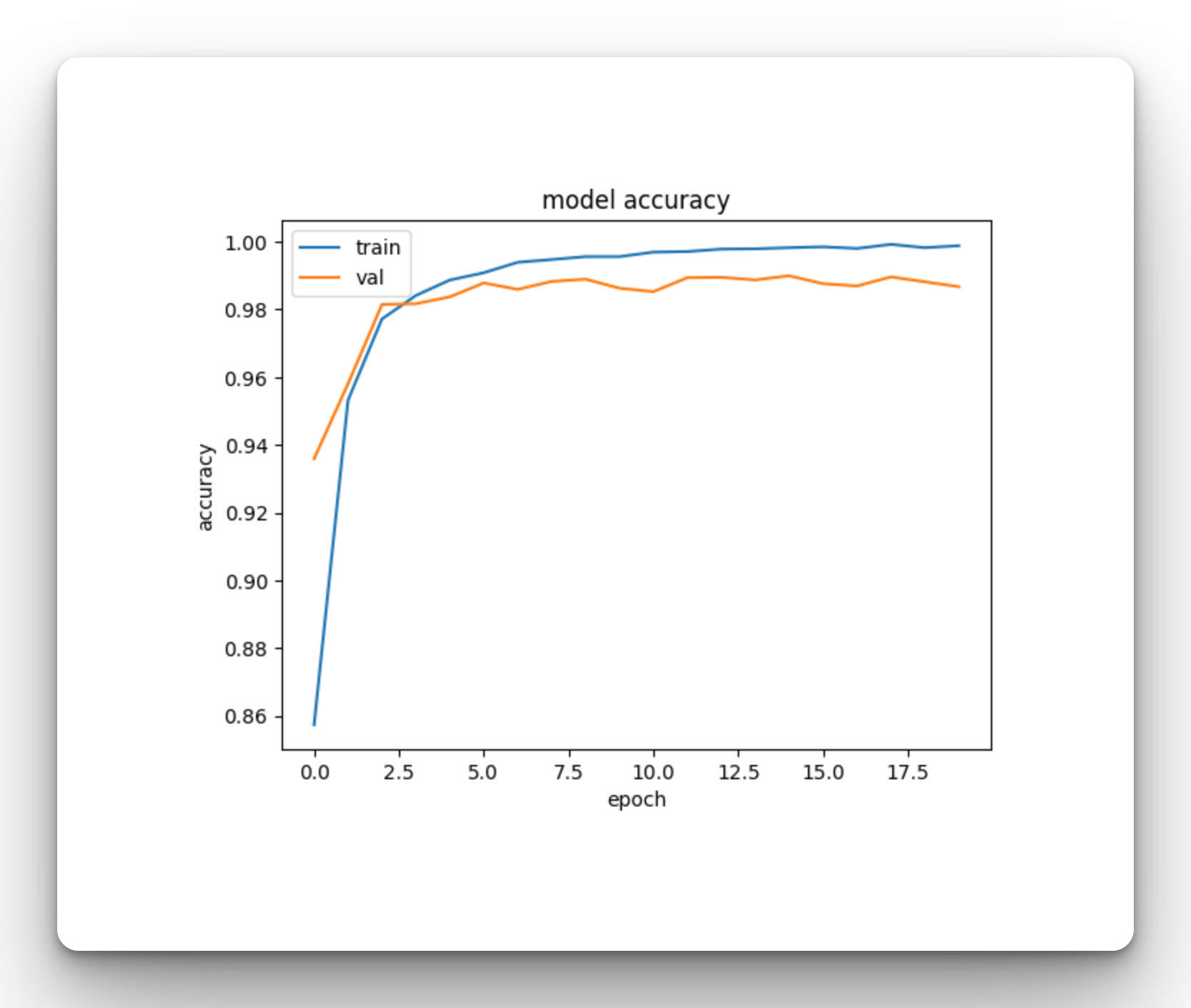
Final Thoughts
Some of the things you could do to improve this model include:
- Use a different metric because the dataset is slightly imbalanced
- Try a Transformer network instead
- Source a different and better dataset