
GPT Instruction Fine-tuning With Keras


Fine-tuning has become the new training because training large language models (LLMs) from scratch is computationally expensive. It also requires collecting and preparing large datasets which is also time intensive. These resources are only the purview of a few individuals and organizations. Fortunately, there are many open-source LLMs that one can leverage for different use cases. For instance, you can fine-tune a GPT model to follow instructions.
These large language models can be fine-tuned on commodity GPUs such as the ones offered for free on Kaggle notebooks or Colab. To fine-tune the model you will need:
- An environment with at least one GPU, such as the ones mentioned above
- An open-source model, such as the ones offered by Kerasnlp
- A dataset for fine-tuning the model which you can create from scratch or pick from Kaggle Datasets or Hugging Face datasets
You will also need to ensure that the dataset is in the required instruction format. There are many formats and any of them will get the job done. You just need to pick one and format the training dataset in that style. A few popular formats include the Alpaca style and the Llama style.
This article will explore how to fine-tune the GPT-2 model using Kerasnlp to follow instructions in the Alpaca style. You can follow along with this Kaggle notebook.
mlnuggets newsletter
Join the newsletter to receive the technical deep dives in your inbox.
Preparing Data for Instruction following
The data for training the model must be a set of instructions followed by the desired responses. First, prepare a prompt template:
prompt_template = """
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Instruction
### Input:
Input
### Response:
"""Next, load a dataset with the instructions, input, and response. The alpaca dataset is a good option here. Load it and convert it into a Pandas DataFrame.
qa_data = load_dataset("tatsu-lab/alpaca", split="train")
import pandas as pd
df = pd.DataFrame(qa_data)
df.head()Create an empty list and populate it with the dataset after replacing the instruction, input, and response as in the provided dataset.
examples = df.to_dict()
num_examples = len(examples["input"])
qa_finetuning_dataset = []
for i in range(num_examples):
input = examples["output"][i]
output = examples["output"][i]
instruction = examples["instruction"][i]
text_with_prompt_template = prompt_template.format(output=output, instruction=instruction, input=input)
qa_finetuning_dataset.append({"text": text_with_prompt_template})
from pprint import pprint
print("One sample from the data:")
pprint(qa_finetuning_dataset[0])Optionally, you can convert it to a Pandas DataFrame and upload it to your Hugging Face account for future reference.
qa_llm_data = pd.DataFrame(columns=["text"], data=qa_finetuning_dataset)
qa_llm_data.head()
from datasets import Dataset
dataset = Dataset.from_pandas(qa_llm_data)
dataset.push_to_hub("YOUR_USERNAME/alpaca", token="YOUR_HF_TOKEN")Fortunately, the Alpaca dataset already contains the formatted dataset in the text column.
Import the required packages and move on to the next step:
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import keras_nlp
import datasets
from datasets import load_dataset
import pandas as pdLoad Instruction Tuning Dataset
Load the Alpaca dataset into a Pandas DataFrame. Select the text column since it contains the data we need to train the model.
dataset = load_dataset("tatsu-lab/alpaca", split="train")
df = pd.DataFrame(dataset)
df = df[['text']]
df.head()
Split the data into a training and validation set. We use 90% for training the model and the rest for validation.
n = int(0.9 * len(df)) # first 90% will be train, rest val
train_examples = df[:n]
val_examples = df[n:]Create TensorFlow Dataset
Next, convert the dataset into a TensorFlow dataset.
train_examples = tf.data.Dataset.from_tensor_slices((train_examples))
val_examples = tf.data.Dataset.from_tensor_slices((val_examples))
Tune the dataset for performance by batching and prefetching to ensure the data loading process is not a bottleneck when training the model.
BUFFER_SIZE = 20000
BATCH_SIZE = 32
def make_batches(ds):
return (
ds.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.prefetch(buffer_size=tf.data.AUTOTUNE)
)
# Create training and validation set batches
train_batches = make_batches(train_examples)
val_batches = make_batches(val_examples)Train Instruction Fine-tuned Model With Kerasnlp
To train the model, we need to define the following items:
- The GPT model
- The model preprocessor that is responsible for tokenization and other preprocessing functions
- The training loss
- Training metrics
- Number of training epochs
Using a learning rate with PolynomialDecay leads to a model with good results. It aims to reach the end learning rate in the given decay steps by applying the polynomial decay function. The steps are used for computing the decayed learning rate.
num_epochs = 5
learning_rate = tf.keras.optimizers.schedules.PolynomialDecay(
5e-5,
decay_steps=train_batches.cardinality() * num_epochs,
end_learning_rate=0.0,
)
optimizer = tf.keras.optimizers.Adam(learning_rate)
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
Next, define the preprocessor and model. The GPT2CausalLM class provides a GPT-2 model for text generation. A causal model works by predicting the next work, given a sequence of words. The preprocessor automatically applies all the required preprocessing to the input string. To perform no preprocessing, pass the preprocessor as None, in which case you will need to process the data before passing it to the model.
preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=300,
)
generator = keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en", preprocessor=preprocessor
)We set the sequence_length to 300 for fast training and the ability to fit the model and data into a single GPU.
mlnuggets newsletter
Join the newsletter to receive the technical deep dives in your inbox.
Compile the model using the default sampler. Kerasnlp provides keras_nlp.samplers for controlling the text generation process. The default method is top_k.
generator.compile(
optimizer=optimizer,
loss=loss,
weighted_metrics=["accuracy"],
)Train the model for 5 epochs. This will take ~2 hours on Kaggle.
history = generator.fit(train_batches, validation_data=val_batches,epochs=num_epochs)
Prompt the model using the generate method:
prompt = "How to make banana bread?"
output = generator.generate(f"### Instruction:\n{prompt}\n### Response:\n", max_length=300)
print(output)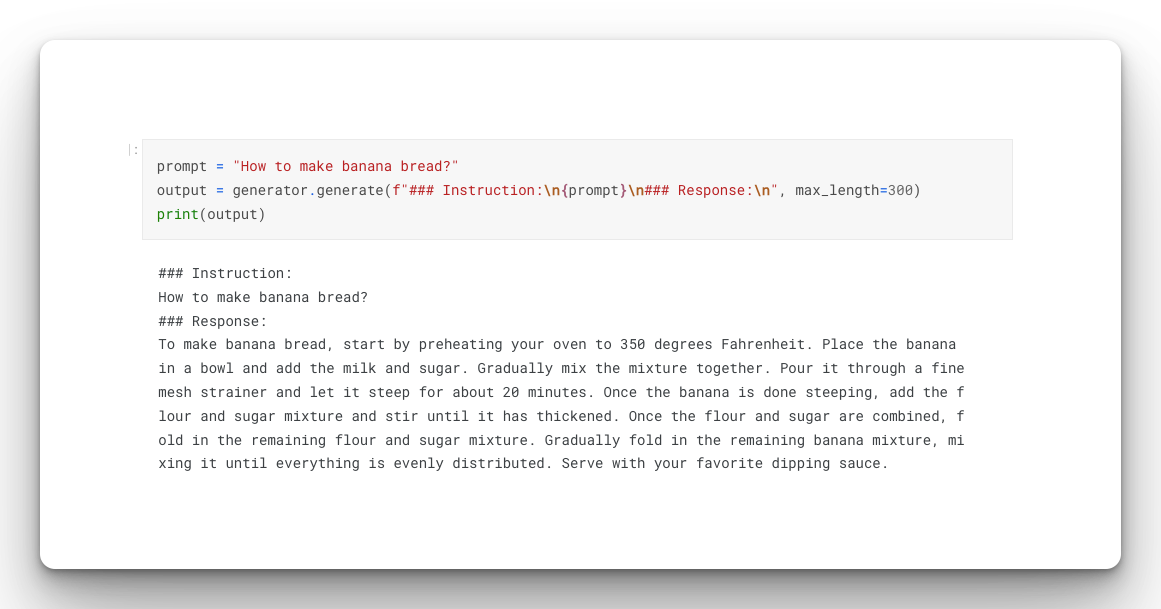
Before fine-tuning the response would have been:
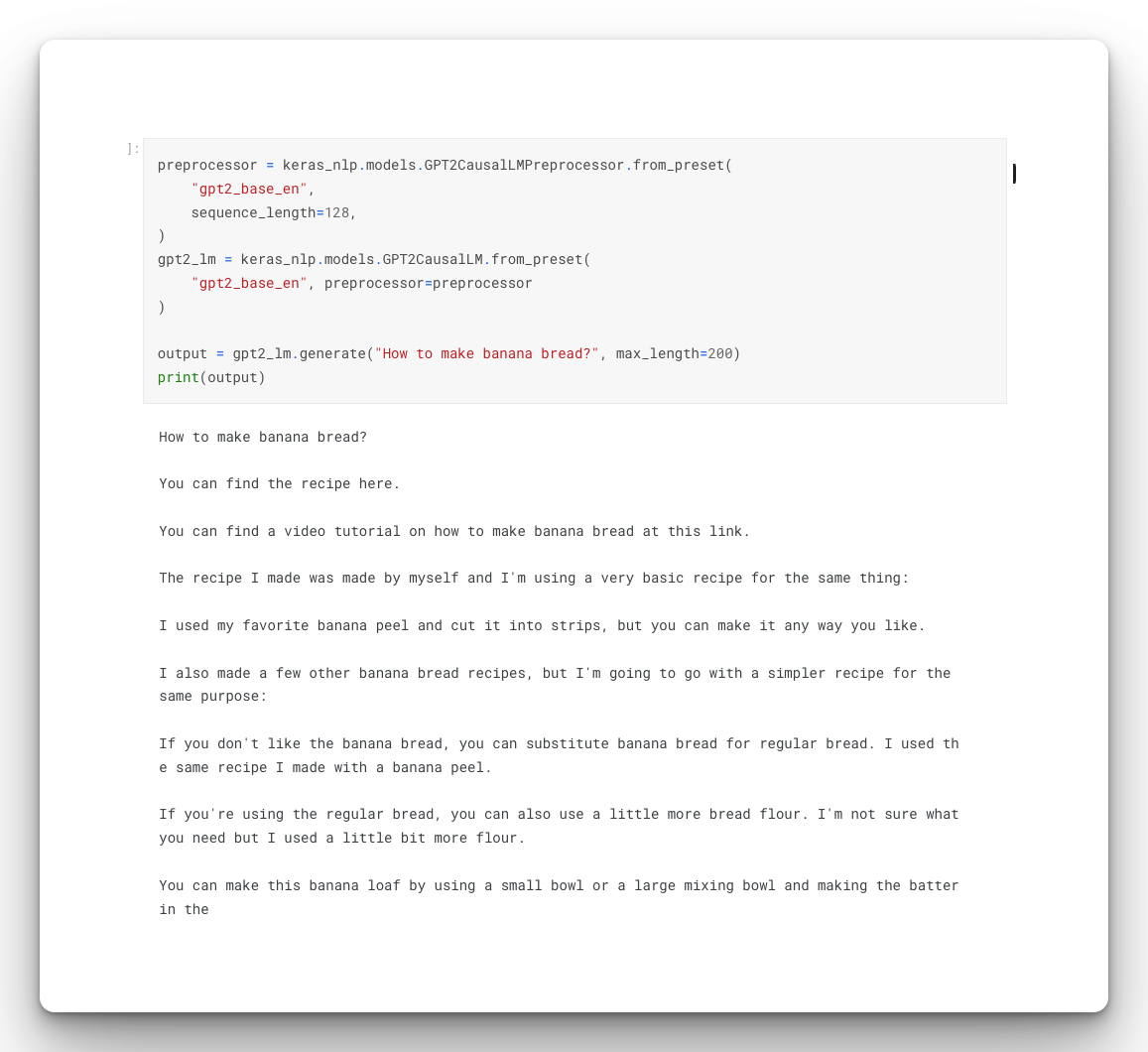
Final Thoughts
In this blog post, you have learned how to perform instruction fine-tuning using Keras. The resulting model can follow instructions, unlike the base model. You can improve on this model by:
- Training for more epochs
- Using a larger dataset
- Fine-tuning using a larger GPT-2 model instead of the base version such as
gpt2_medium_en,gpt2_large_en, orgpt2_extra_large_en. - Try a different generative model such as Llama