
Text Classification With BERT and KerasNLP


BERT is a popular Masked Language Model. Some words are hidden from the model and trained to predict them. The model is bidirectional, meaning it has access to the words to the left and right, making it a good choice for tasks such as text classification.
Training BERT can quickly become complicated, but not with KerasNLP, which provides a simple Keras API for training and finetuning natural language processing (NLP)models. KerasNLP provides preprocessors and tokenizers for various NLP models, including BERT, GPT2, and OPT. You can even use the library to train a transformer from scratch.
In this article, you will use KerasNLP to train a text classification model to classify sentiment.
Let's dive in.
mlnuggets newsletter
Join the newsletter to receive the technical deep dives in your inbox.
Getting Started
Install KerasNLP:
pip install keras-nlp --upgradeImport the required packages:
import tensorflow as tf
import numpy as np
import pandas as pd
from tensorflow import keras
import keras_nlp
from sklearn.model_selection import train_test_split
You can follow along using this Kaggle Notebook.
Load NLP Dataset
Next, download the training dataset from Google Drive.
wget --no-check-certificate https://drive.google.com/uc?id=13ySLC_ue6Umt9RJYSeM2t-V0kCv-4C-P -O /tmp/sentiment.csv -O /tmp/sentiment.csv
Process NLP Dataset
Read the dataset and split it into a training and testing set.
df = pd.read_csv('/tmp/sentiment.csv')
X = df['text']
y = df['sentiment']
X_train, X_test , y_train, y_test = train_test_split(X, y , test_size = 0.20)
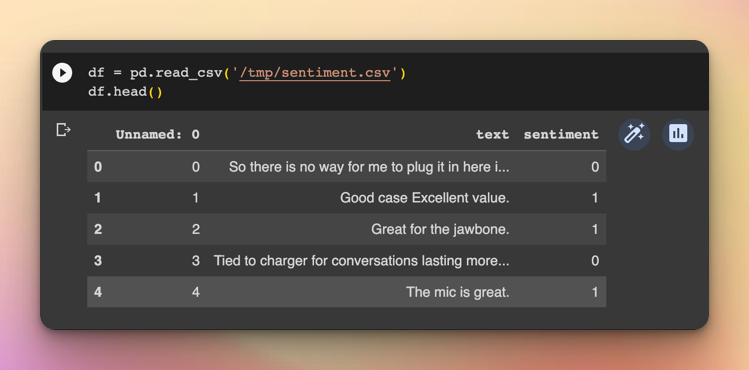
Convert the labels to the categorical format as expected by Keras.
y_train = tf.keras.utils.to_categorical(y_train, num_classes=2, dtype='float32')
y_test = tf.keras.utils.to_categorical(y_test, num_classes=2, dtype='float32')
Load Pretrained BERT Model
KerasNLP provides various NLP modes to choose from. In this case, let's use the bert_tiny_en_uncased_sst2 that has been finetuned for sentiment analysis. The model is loaded using BertClassifier with the following arguments:
- The model name
- The number of classes, here 2
- Whether to load the pre-trained weights, true by default
- The type of activation. We choose sigmoid because it's a binary classification problem.
model_name = "bert_tiny_en_uncased_sst2"
# Pretrained classifier.
classifier = keras_nlp.models.BertClassifier.from_preset(
model_name,
num_classes=2,
load_weights = True,
activation='sigmoid'
)
Train BERT Model With KerasNLP
The next step is to compile and train the model. Set the trainable parameter of the model to false so that you are not training the model from scratch. The objective is to use the pre-trained model and finetune it on your dataset, a process known as transfer learning.
classifier.compile(
loss=keras.losses.BinaryCrossentropy(),
optimizer=keras.optimizers.Adam(),
jit_compile=True,
metrics=["accuracy"],
)
# Access backbone programatically (e.g., to change `trainable`).
classifier.backbone.trainable = False
# Fit again.
classifier.fit(x=X_train, y=y_train, validation_data=(X_test,y_test), batch_size=32)Evaluating the model on the test set gives us an accuracy of 87% which is not bad considering that you have used the tiny version of the BERT model.
classifier.evaluate(X_test, y_test,batch_size=32)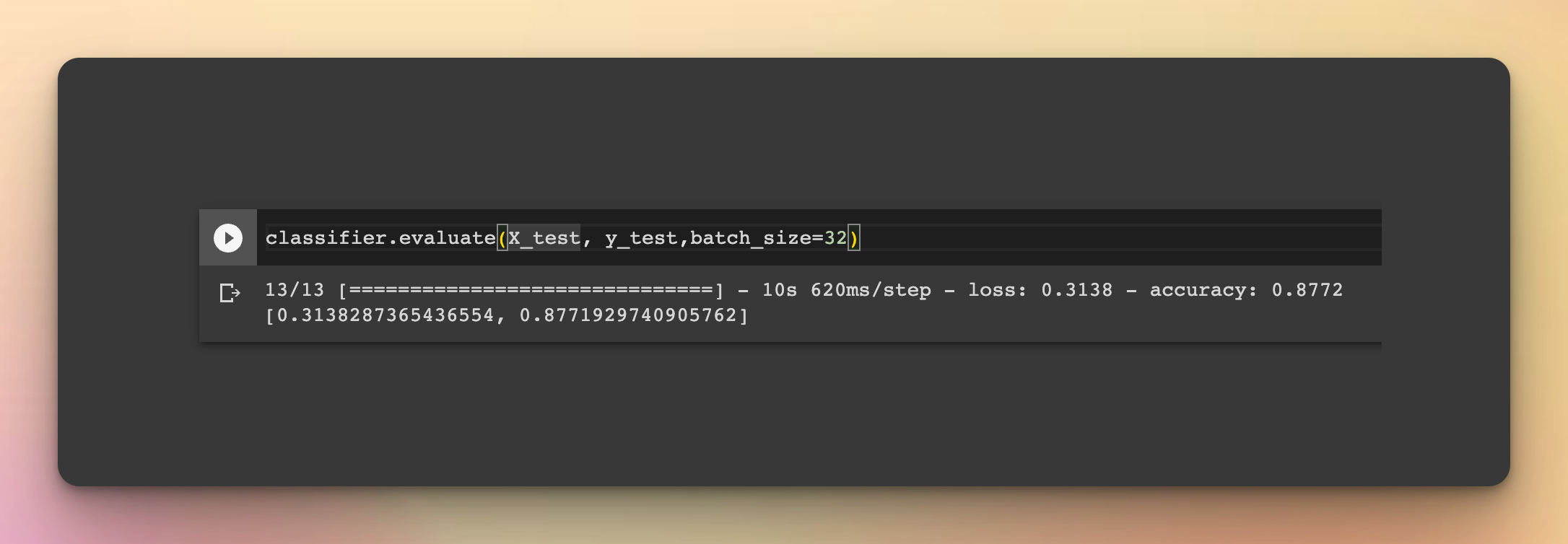
mlnuggets newsletter
Join the newsletter to receive the technical deep dives in your inbox.
Predict Using Trained BERT Model
Test the BERT model to see how it performs on new data samples.
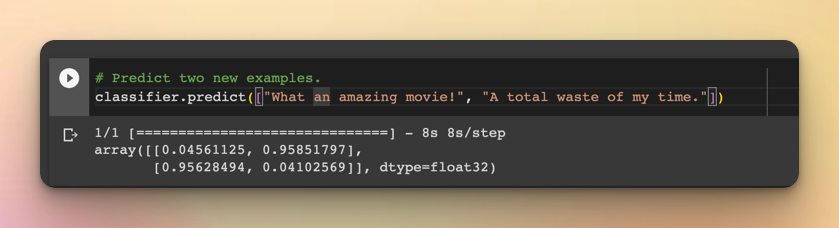
# Predict two new examples.
classifier.predict(["What an amazing movie!", "A total waste of my time."])The model predicts that the first sample is positive with 95% while the second one is negative with 95% confidence.
You can also make the results more interpretable by passing the predictions through the class names of the training data. Here is an example with a sample from the test set:
print(list(X_test)[10])
class_names = ["negative","postive"]
scores = classifier.predict([list(X_test)[10]])
scores
f"{class_names[np.argmax(scores)]} with a { (100 * np.max(scores)).round(2) } percent confidence." 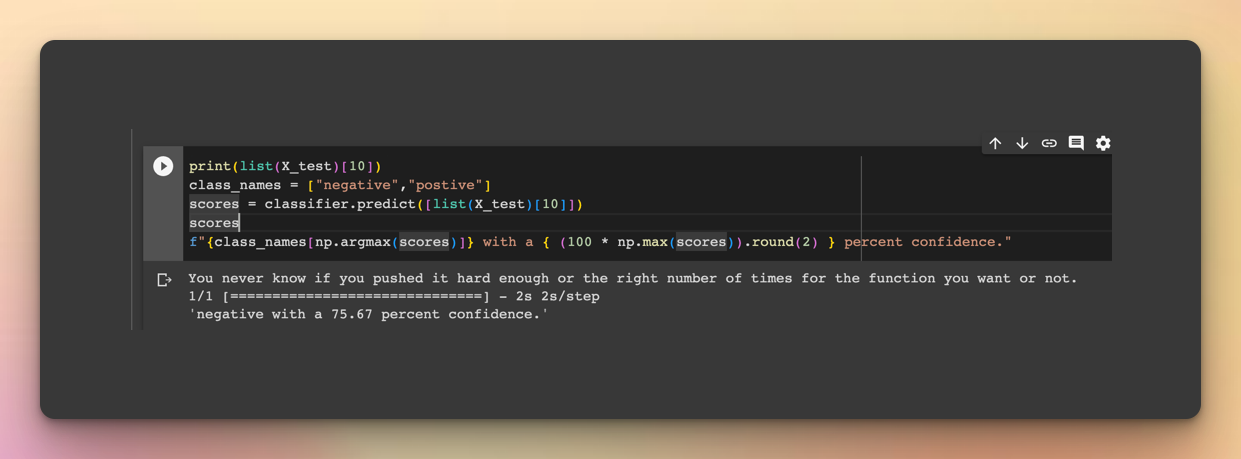
Finetune BERT With User-controlled Preprocessing
In the previous example, you trained a BERT model by passing raw strings. Notice that we didn't perform the standard NLP processing, such as:
- Removing punctuations
- Removing stop words
- Creating vocabulary
- Converting the text to a numerical computation
All these were done by the model automatically. However, in some cases, you may want more control over that process. KerasNLP provides BertPreprocessor for this purpose. Every model has its preprocessor class. For this illustration, load BertPreprocessor with a sequence length of 128.
preprocessor = keras_nlp.models.BertPreprocessor.from_preset(
model_name,
sequence_length=128,
) Manually map this preprocessor to the training and testing set. Convert the data to a tf.data format to make this possible. Notice the use of:
cacheto cache the dataset. Pass a file name to this function if your dataset can't fit into memory.-
AUTOTUNEto automatically configure the batch size.
training_data = tf.data.Dataset.from_tensor_slices(([X_train], [y_train]))
validation_data = tf.data.Dataset.from_tensor_slices(([X_test], [y_test]))
train_cached = (
training_data.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
)
test_cached = (
validation_data.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
)Next, define the BERT model and train it.
# Pretrained classifier.
classifier = keras_nlp.models.BertClassifier.from_preset(
model_name,
preprocessor=None,
num_classes=2,
load_weights = True,
activation='sigmoid'
)
classifier.compile(
loss=keras.losses.BinaryCrossentropy(),
optimizer=keras.optimizers.Adam(),
jit_compile=True,
metrics=["accuracy"],
)
classifier.fit(train_cached, validation_data=test_cached,epochs=10)You can run some predictions on new data by first passing it through the BERT preprocessor to ensure that it's in the format the model expects.
test_data = preprocessor([list(X_test)[10]])
print(list(X_test)[10])
scores = classifier.predict(test_data)
scores
f"{class_names[np.argmax(scores)]} with a { (100 * np.max(scores)).round(2) } percent confidence." 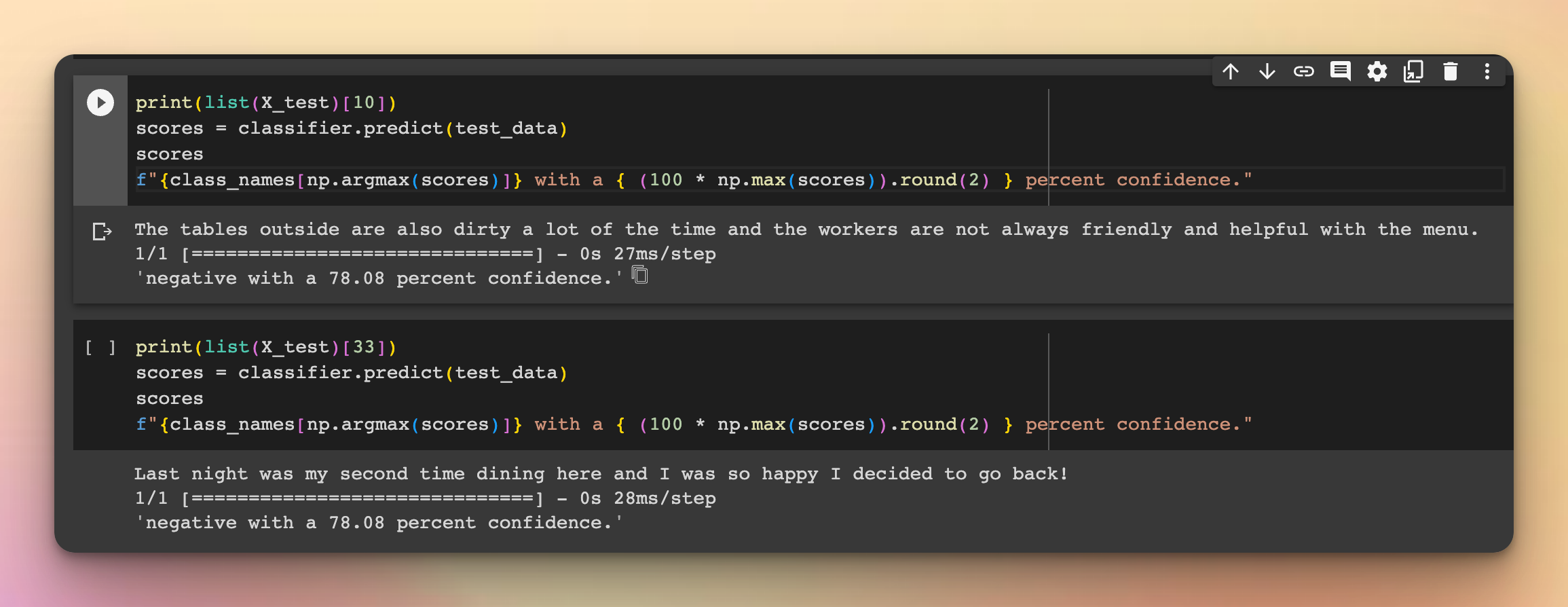
mlnuggets newsletter
Join the newsletter to receive the technical deep dives in your inbox.
Final Thoughts
You have seen how easy it is to train NLP models with KerasNLP, which removes much of the complexity, enabling you to train the model faster. KerasNLP is an excellent choice for training NLP models with TensorFlow using the Keras API you are already familiar with. You can explore further by switching the dataset and model used in this article. Check out the KerasNLP website for more tutorials and guides.
Whenever you're ready, there is 2 way I can help you:
If you're looking to accelerate your career, I'd recommend starting with an affordable ebook:
→ Writing for Data Scientists: The exact path I followed to get technical work that pays between $250-$500 from machine learning companies such as Comet, Neptune, cnvrg, Paperspace, Layer, Neural Magic, Determined, Activeloop, and many more. Get your copy.
→ Data Science and Machine Learning Ebook: I offer numerous free and paid data science and machine learning ebooks to help you in your data science and machine learning career. Check them out.