
Distributed training with TensorFlow: How to train Keras models on multiple GPUs

Training computer vision models requires a lot of time because of the size of the models and image data. Therefore, training these models can take prolonged periods of time, especially when training on a single GPU. You can reduce the training time by distributing the training across several GPUs. This article will teach you how to train a TensorFlow image classification model on multiple GPUs.
Data loading with TensorFlow
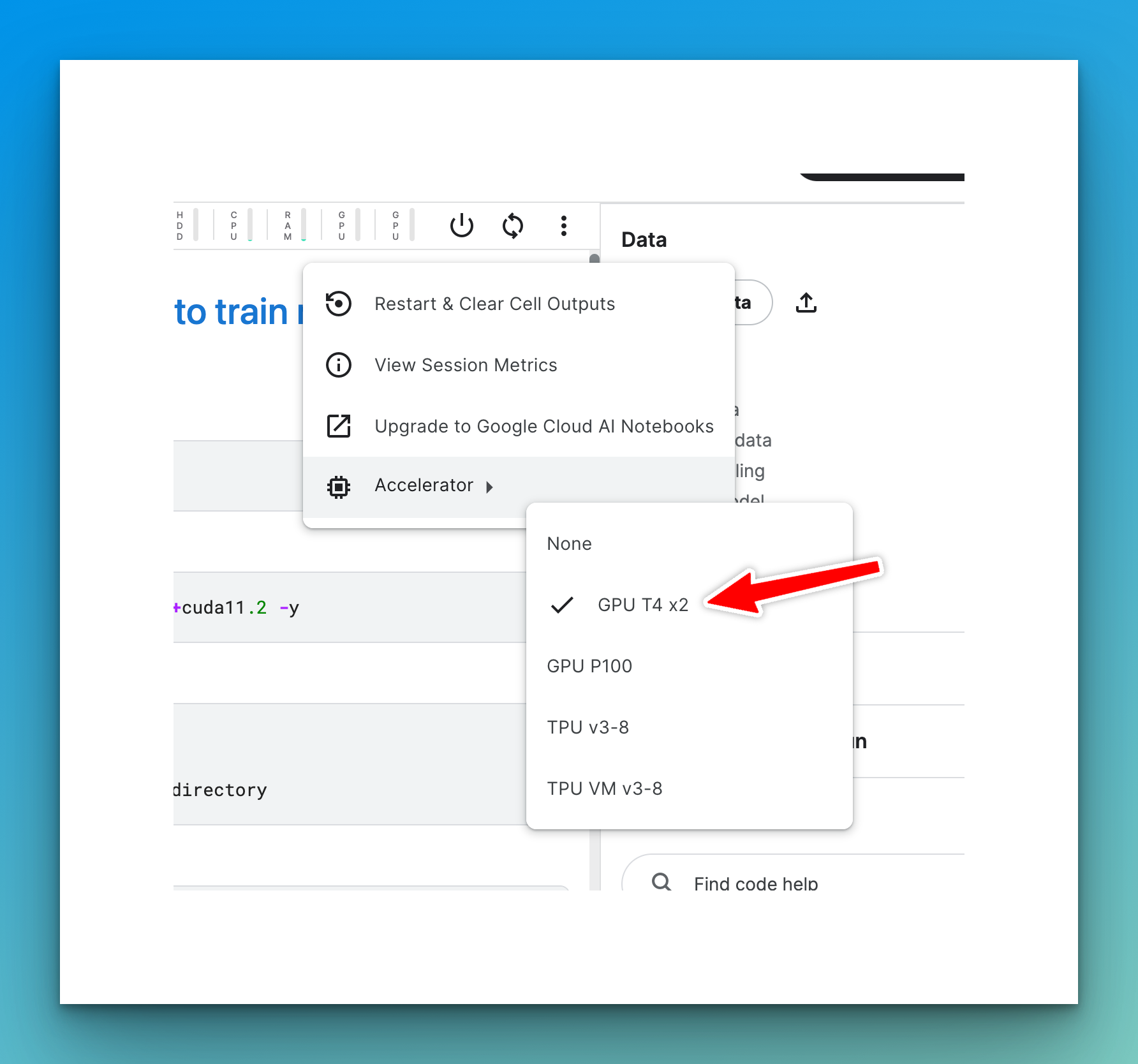
The data you will use is provided by Hugging Face for the AI or Not image classification competition. You can follow along with this Kaggle Notebook. Select the accelerator option with 2 GPUs.
The first step is to load the data from the directory containing the images.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing import image_dataset_from_directory
size = 224
training_set = image_dataset_from_directory("/kaggle/input/aidata/train",shuffle=True,batch_size=32,image_size=(size, size))
val_dataset = image_dataset_from_directory("/kaggle/input/aidata/val",shuffle=True,batch_size=32,image_size=(size, size))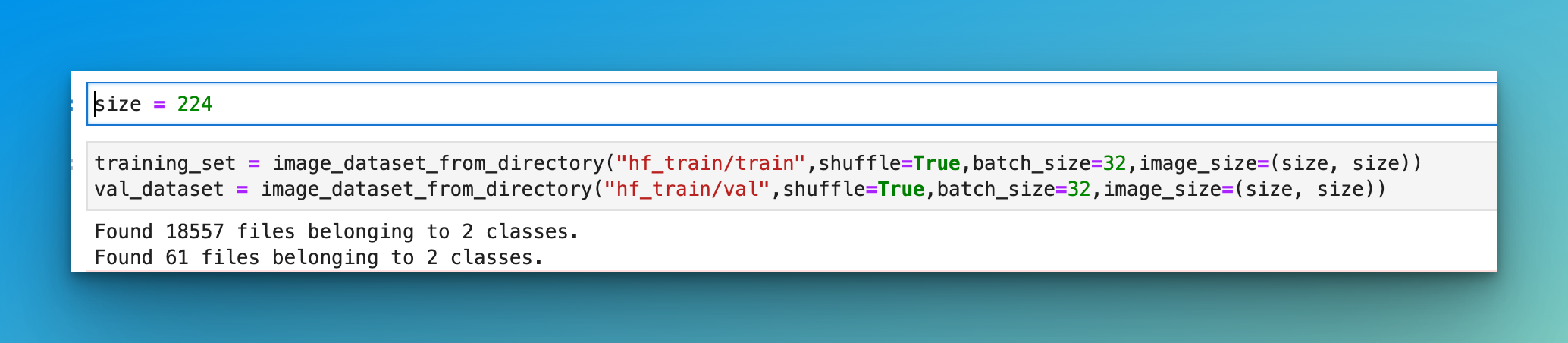
Check our How to build CNN in TensorFlow tutorial.
Data augmentation with Keras
Image augmentation helps improve the mode's performance by exposing it to images at various angles and aspect ratios.
Let's perform some basic image augmentation.
data_augmentation = keras.Sequential(
[keras.layers.RandomFlip("horizontal_and_vertical"),
keras.layers.RandomRotation(0.2),
])Visualizing image data with Matplotlib
Visualize the images using Matplotlib based on the augmentations defined above.
import numpy as np
import matplotlib.pyplot as plt
for images, labels in training_set.take(1):
plt.figure(figsize=(12, 12))
first_image = images[0]
for i in range(12):
ax = plt.subplot(3, 4, i + 1)
augmented_image = data_augmentation(
tf.expand_dims(first_image, 0)
)
plt.imshow(augmented_image[0].numpy().astype("int32"))
plt.axis("off")
Distributed training with Keras
TensorFlow provides various strategies for distributed training. One of them is the MirroredStrategy which allows distributed training on multiple GPUs on a single machine. It creates one replica per GPU and mirrors all model variables across the replicas. The variables form one variable called MirroredVariable .
Apply a EfficientNetV2M via transfer learning. To train the model with mirrored strategy, create a mirrored_strategy.scope() and define the model within that scope.
Apart from the model, the metrics and optimizer must be defined within the scope. Creating the variables within this scope leads to the creation of distributed variables.
Train the model normally after defining the variables within the mirrored_strategy scope. MirroredStrategy will perform the training on all the available GPUs or the one you'd define manually.
mirrored_strategy = tf.distribute.MirroredStrategy()
with mirrored_strategy.scope():
base_model = tf.keras.applications.EfficientNetV2M(
weights='imagenet',
input_shape=(size, size, 3),
include_top=False)
base_model.trainable = False
inputs = keras.Input(shape=(size, size, 3))
x = data_augmentation(inputs)
x = tf.keras.applications.efficientnet_v2.preprocess_input(x)
x = base_model(x, training=False)
x = keras.layers.GlobalAveragePooling2D()(x)
x = keras.layers.Dropout(0.2)(x)
outputs = keras.layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
accuracy = keras.metrics.BinaryAccuracy()
optimizer = tf.keras.optimizers.Adam()
model.compile(optimizer=optimizer, loss=tf.keras.losses.BinaryCrossentropy(),metrics=accuracy)
model.fit(training_set, epochs=10, validation_data=val_dataset)Notice that the two GPUs on Kaggle are being used.
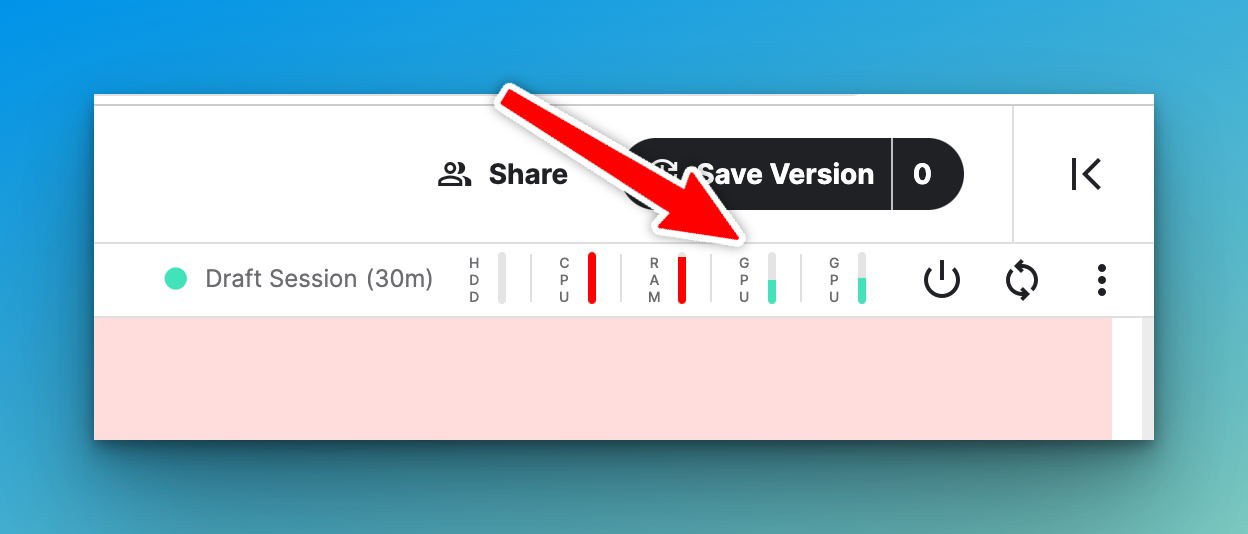
Final thoughts
There are other training strategies you can try apart from the mirrored strategy; they include:
TPUStrategyfor training on TPUs.-
MultiWorkerMirroredStrategyfor distributed training across multiple workers. ParameterServerStrategya data-parallel method for training on multiple machines.CentralStorageStrategyperforms synchronous training without mirroring variables but places them on the CPU.
Whenever you're ready, there is 2 way I can help you:
If you're looking for a way to build a career while writing about data science and machine learning, I'd recommend starting with an affordable ebook:
→ Writing for Data Scientists: The exact path I followed to get technical work that pays between $250-$500 from machine learning companies such as Comet, Neptune, cnvrg, Paperspace, Layer, Neural Magic, Determined, Activeloop, and many more. Get your copy.
→ Data Science and Machine Learning Ebook: I offer numerous free and paid data science and machine learning ebooks to help you in your data science career. Check them out.