
Distributed training with JAX & Flax


Training models on accelerators with JAX and Flax differs slightly from training with CPU. For instance, the data needs to be replicated in the different devices when using multiple accelerators. After that, we need to execute the training on multiple devices and aggregate the results. Flax supports TPU and GPU accelerators.
In the last article, we saw how to train models with the CPU. This article will focus on training models with Flax and JAX using GPUs and TPU.

Perform standard imports
You'll need to install Flax for this illustration.
pip install flax
Let's import all the packages we'll use in this project.
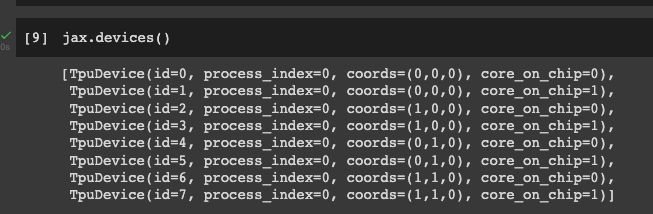
Setup TPUs on Colab
Change the runtime on Colab to TPUs. Next, run the code below to set up JAX to use TPUs.
Download the dataset
We'll use the cats and dogs dataset from Kaggle. Let's start by downloading and extracting it.
Load the dataset
We'll use existing data loaders to load the data since JAX and Flax don't ship with any data loaders. In this case, let's use PyTorch to load the dataset. The first step is to set up a dataset class.
Next, we create a DataFrame containing the categories.
We then use the dataset class to create training and testing data. We also apply a custom function to return the data as NumPy arrays. Later, we'll use this train_loader when training the model. We'll then evaluate it on a batch of the test data.
Define the model with Flax
In Flax, models are defined using the Linen API. It provides the building blocks for defining convolution layers, dropout, etc.

Networks are created by subclassing Module. Flax allows you to define your networks using setup or nn.compact . Both approaches behave the same way but nn.compact is more concise.
Create training state
We now need to create parallel versions of our functions. Parallelization in JAX is done using the pmap function. pmap compiles a function with XLA and executes it on multiple devices.
Apply the model
The next step is to define parallel apply_model and update_modelfunctions. The apply_model function:
- Computes the loss.
- Computes predictions from all devices by calculating the average of the probabilities using
jax.lax.pmean().
Notice the use of the axis_name. You can give this any name. You'll need to specify that when computing the mean of the probabilities and accuracies.
The update_model function updates the model parameters.
Training function
The next step is to define the model training function. In the function, we:
- Replicate the training data at batch level using
jax_utils.replicate. apply_modelto the replicated data.- Obtain the epoch loss and accuracy and unreplicate them using
jax_utils.unreplicate. - Compute the mean of the loss and accuracy.
apply_modelto the test data and obtain test metrics.- Print the training and evaluation metrics per epoch.
- Append the training and test metrics to lists for visualization later.
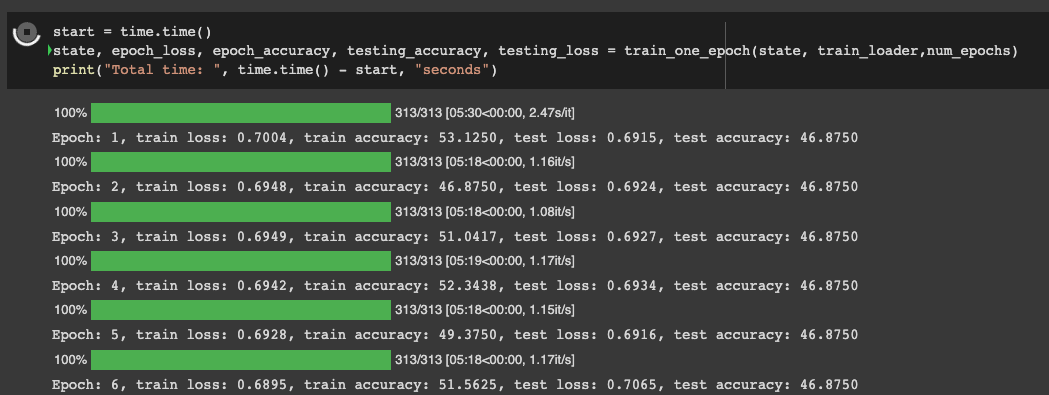
Train the model
When creating the training state, we generate pseudo-random numbers equivalent to the number of devices. We also replicate a small batch of the test data for testing. The next step is to run the training function and unpack the training and test metrics.
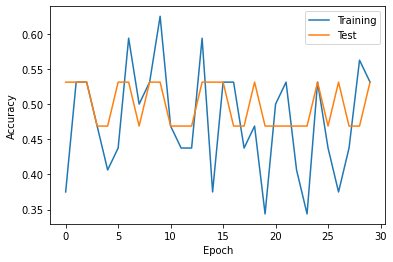
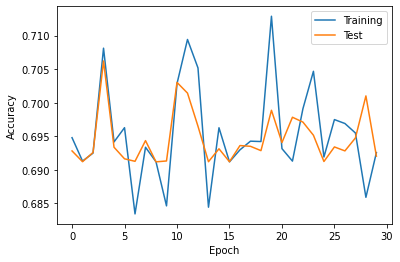
Model evaluation
The metrics obtained above can be used to plot the metrics.
Final thoughts
This article shows how you can use JAX and Flax to train machine learning models in parallel on multiple devices. You have seen that the process involves making a few functions parallel using JAX's pmap function. We have also covered how to replicate the training and test data on multiple devices.
Resources
- What is JAX?
- Elegy(High-level API for deep learning in JAX & Flax)
- Flax vs. TensorFlow
- How to load datasets in JAX with TensorFlow
- JAX loss functions
- Optimizers in JAX and Flax
- Image classification with JAX & Flax
- How to use TensorBoard in Flax
- LSTM in JAX & Flax
 mlnuggets
mlnuggetsFollow us on LinkedIn, Twitter, GitHub, and subscribe to our blog, so you don't miss a new issue.