
Flax vs. TensorFlow


Flax is the neural network library for JAX. TensorFlow is a deep learning library with a large ecosystem of tools and resources. Flax and TensorFlow are similar but different in some ways. For instance, both Flax and TensorFlow can run on XLA.
Let's look at the differences between Flax and TensorFlow from my perspective as a user of both libraries.
Random number generation in TensorFlow and Flax
In TensorFlow, you can set global or function level seeds. Generating random numbers in TensorFlow is quite straightforward.
tf.random.set_seed(6853)However, this is not the case in Flax. Flax is built on top of JAX. JAX expects pure functions, meaning functions without any side effects. To achieve this JAX introduces stateless pseudo-random number generators (PRNGs). For example, calling the random number generator from NumPy will result in a different number every time.
import numpy as np
print(np.random.random())
print(np.random.random())
print(np.random.random())
In JAX and Flax, the result should be the same on every call. We, therefore, generate random numbers from a random state. The state should not be re-used. It can be split to obtain several pseudo-random numbers.
import jax
key = jax.random.PRNGKey(0)
key1, key2, key3 = jax.random.split(key, num=3)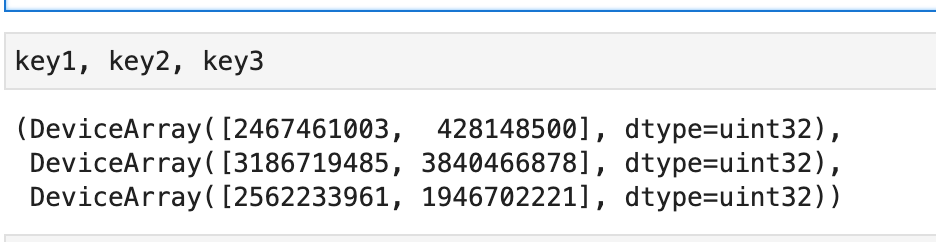
Model definition in Flax and TensorFlow
Model definition in TensorFlow is made easy by the Keras API. You can use Keras to define Sequential or Functional networks. Keras has many layers for designing various types of networks, such as CNNs, and LSTMS.
Read more: How to build TensorFlow models with the Keras Functional API
In Flax, networks are designed using the setup or compact way. The setup method is explicit, while the compact way is in-line. Setup is very similar to how networks are designed in PyTorch. For example, here is a network designed with the setup way.
class MLP(nn.Module):
def setup(self):
# Submodule names are derived by the attributes you assign to. In this
# case, "dense1" and "dense2". This follows the logic in PyTorch.
self.dense1 = nn.Dense(32)
self.dense2 = nn.Dense(32)
def __call__(self, x):
x = self.dense1(x)
x = nn.relu(x)
x = self.dense2(x)
return xHere's the same network designed in a compact way. The compact way is more straightforward because there is less code duplicity.
class MLP(nn.Module):
@nn.compact
def __call__(self, x):
x = nn.Dense(32, name="dense1")(x)
x = nn.relu(x)
x = nn.Dense(32, name="dense2")(x)
return xCheck our Image classification with JAX & Flax article to learn more about designing networks in JAX and Flax.
Activations in Flax and TensorFlow
The tf.keras.activations module in TensorFlow provides most of the activations needed when designing networks. In Flax, activation functions are available via the linen module.
Read more: Activation functions in JAX and Flax
Optimizers in Flax and TensorFlow
The tf.keras.optimizers in TensorFlow has popular optimizer functions. However, Flax doesn't ship with any optimizer functions. Optimizers used in Flax are provided by another library known as Optax.
Read more: Optimizers in JAX and Flax
Metrics in Flax and TensorFlow
In TensorFlow, metrics are available via the tf.keras.metrics module. As of this writing, Flax has no metrics module. You'll need to define metric functions for your networks or use other third-party libraries.
import optax
import jax.numpy as jnp
def compute_metrics(logits, labels):
loss = jnp.mean(optax.softmax_cross_entropy(logits, jax.nn.one_hot(labels, num_classes=2)))
accuracy = jnp.mean(jnp.argmax(logits, -1) == labels)
metrics = {
'loss': loss,
'accuracy': accuracy
}
return metricsRead more: JAX loss functions
Computing gradients in Flax and TensorFlow
The jax.grad function is used to compute gradients in Flax. It offers the ability to return auxillary data. For example, you can return loss and gradients at the same time.
@jax.jit
def sum_logistic(x):
return jnp.sum(1.0 / (1.0 + jnp.exp(-x))),(x + 1)
x_small = jnp.arange(6.)
derivative_fn = jax.grad(sum_logistic, has_aux=True)
print(derivative_fn(x_small))
# (DeviceArray([0.25 , 0.19661194, 0.10499357, 0.04517666, 0.01766271,
# 0.00664806], dtype=float32), DeviceArray([1., 2., 3., 4., 5., 6.], dtype=float32))
Advanced automatic differentiation can also be done using jax.vjp() and jax.jvp().
Read more: JAX (What it is and how to use it in Python)
In TensorFlow, gradients are computed using tf.GradientTape.
def grad(model, inputs, targets):
with tf.GradientTape() as tape:
loss_value = loss(model, inputs, targets, training=True)
return loss_value, tape.gradient(loss_value, model.trainable_variables)Unless you are creating custom training loops in TensorFlow, you will not define a gradient function. This is done automatically when you train the network.
Loading datasets in Flax and TensorFlow
TensorFlow provides utilities for loading data. Flax doesn't ship with any data loaders. You have to use the data loaders from other libraries such as TensorFlow. As long as the data is in JAX NumPy or regular arrays and has the proper shape, it can be passed to Flax networks.
Read more: How to load datasets in Flax with TensorFlow
Training model in Flax vs. TensorFlow
Training models in TensorFlow is done by compiling the network and calling the fit method. However, in Flax, we create a training state to hold the training information and then pass data to the network.
from flax.training import train_state
def create_train_state(rng):
"""Creates initial `TrainState`."""
model = LSTMModel()
params = model.init(rng, jnp.array(X_train_padded[0]))['params']
tx = optax.adam(0.001,0.9,0.999,1e-07)
return train_state.TrainState.create(
apply_fn=model.apply, params=params, tx=tx)After that, we define a training step that will compute the loss and gradients. It then uses these gradients to update the model parameters and returns the model metrics and the new state.
@jax.jit
def train_step(state, text, labels):
def loss_fn(params):
logits = LSTMModel().apply({'params': params}, text)
loss = jnp.mean(optax.softmax_cross_entropy(
logits=logits,
labels=jax.nn.one_hot(labels, num_classes=2)))
return loss, logits
grad_fn = jax.value_and_grad(loss_fn, has_aux=True)
(_, logits), grads = grad_fn(state.params)
state = state.apply_gradients(grads=grads)
metrics = compute_metrics(logits, labels)
return state, metricsUse Elegy to train networks like in Keras. Elegy is a high-level API for JAX neural network libraries.
Distributed training in Flax and TensorFlow
Training networks in TensorFlow in a distributed manner is done by creating distributed strategy.
mirrored_strategy = tf.distribute.MirroredStrategy()
with mirrored_strategy.scope():
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))])
model.compile(loss='mse', optimizer='sgd')To train networks in a distributed way in Flax, we define distributed versions of our Flax functions. This is done using the pmap function that executes a function on multiple devices. You'll then compute predictions from all devices and get the average using jax.lax.pmean(). You also need to replicate the data on all the devices using jax_utils.replicate . To obtain metrics from the device use jax_utils.unreplicate.
Read more: Distributed training with JAX & Flax
Working with TPU accelerators
You can use Flax and TensorFlow with TPU and GPU accelerators. To use Flax with TPUs on Colab, you'll need to set it up:
jax.tools.colab_tpu.setup_tpu()
jax.devices()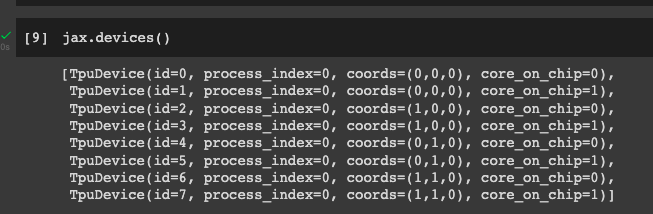
For TensorFlow, set up the TPU distributed strategy.
cluster_resolver = tf.distribute.cluster_resolver.TPUClusterResolver(
tpu=tpu_address)
tf.config.experimental_connect_to_cluster(cluster_resolver)
tf.tpu.experimental.initialize_tpu_system(cluster_resolver)
tpu_strategy = tf.distribute.TPUStrategy(cluster_resolver)Model evaluation
TensorFlow provides the evaluate function for evaluating networks. Flax doesn't ship with such a function. You'll need to create a function that applies the model and returns the test metrics. Elegy provides Keras-like functions such as the evaluate method.
@jax.jit
def eval_step(state, text, labels):
logits = LSTMModel().apply({'params': state.params}, text)
return compute_metrics(logits=logits, labels=labels)
def evaluate_model(state, text, test_lbls):
"""Evaluate on the validation set."""
metrics = eval_step(state, text, test_lbls)
metrics = jax.device_get(metrics)
metrics = jax.tree_map(lambda x: x.item(), metrics)
return metricsVisualize model performance
Model visualizing is similar in Flax and TensorFlow. Once you obtain the metrics, you can use a package such as Matplotlib to visualize the model's performance. You can also use TensorBoard in both Flax and TensorFlow.
Final thoughts
You have seen the differences between the Flax and TensorFlow libraries. In particular, have seen the difference in model definition and training. Interested in exploring JAX and Flax further? Here are more nuggets from our blog:
Follow us on LinkedIn, Twitter, GitHub, and subscribe to our blog, so you don't miss a new issue.