
Elegy(High-level API for deep learning in JAX & Flax)


Training deep learning networks in Flax is done in a couple of steps. It involves creating the following functions:
- Model definition.
- Compute metrics.
- Training state.
- Training step.
- Training and evaluation function.
Flax and JAX give more control in defining and training deep learning networks. However, this comes with more verbosity. Enter Elegy. Elegy is a high-level API for creating deep learning networks in JAX. Elegy's API is like the one in Keras.
Let's look at how to use Elegy to define and train deep learning networks in Flax.
Data pre-processing
To make this illustration concrete, we'll use the movie review data from Kaggle to create an LSTM network in Flax.
Read more: LSTM in JAX & Flax (Complete example with code and notebook)
The first step is to download and extract the data.
import os
import kaggle
# Obtain from https://www.kaggle.com/username/account
os.environ["KAGGLE_USERNAME"]="KAGGLE_USERNAME"
os.environ["KAGGLE_KEY"]="KAGGLE_KEY"
!kaggle datasets download lakshmi25npathi/imdb-dataset-of-50k-movie-reviews
import zipfile
with zipfile.ZipFile('imdb-dataset-of-50k-movie-reviews.zip', 'r') as zip_ref:
zip_ref.extractall('imdb-dataset-of-50k-movie-reviews')Next, we define the following processing steps:
- Split the data into a training and testing set.
- Remove stopwords from the data.
- Clean the data by removing punctuations and other special characters.
- Convert the data to a TensorFlow dataset.
- Conver the data to numerical representation using the Keras vectorization layer.
import numpy as np
import pandas as pd
from numpy import array
import tensorflow_datasets as tfds
import tensorflow as tf
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import tensorflow as tf
df = pd.read_csv("imdb-dataset-of-50k-movie-reviews/IMDB Dataset.csv")
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
def remove_stop_words(review):
review_minus_sw = []
stop_words = stopwords.words('english')
review = review.split()
cleaned_review = [review_minus_sw.append(word) for word in review if word not in stop_words]
cleaned_review = ' '.join(review_minus_sw)
return cleaned_review
df['review'] = df['review'].apply(remove_stop_words)
labelencoder = LabelEncoder()
df = df.assign(sentiment = labelencoder.fit_transform(df["sentiment"]))
df = df.drop_duplicates()
docs = df['review']
labels = array(df['sentiment'])
X_train, X_test , y_train, y_test = train_test_split(docs, labels , test_size = 0.20, random_state=0)
max_features = 10000 # Maximum vocab size.
batch_size = 128
max_len = 50 # Sequence length to pad the outputs to.
vectorize_layer = tf.keras.layers.TextVectorization(standardize='lower_and_strip_punctuation',max_tokens=max_features,output_mode='int',output_sequence_length=max_len)
vectorize_layer.adapt(X_train)
X_train_padded = vectorize_layer(X_train)
X_test_padded = vectorize_layer(X_test)
training_data = tf.data.Dataset.from_tensor_slices((X_train_padded, y_train))
validation_data = tf.data.Dataset.from_tensor_slices((X_test_padded, y_test))
training_data = training_data.batch(batch_size)
validation_data = validation_data.batch(batch_size)
def get_train_batches():
ds = training_data.prefetch(1)
ds = ds.repeat(3)
ds = ds.shuffle(3, reshuffle_each_iteration=True)
# tfds.dataset_as_numpy converts the tf.data.Dataset into an iterable of NumPy arrays
return tfds.as_numpy(ds)
Model definition in Elegy
Start by installing Elegy, Flax, and JAX.
pip install -U elegy flax jax jaxlibNext, define the LSTM model.
import jax
import jax.numpy as jnp
import elegy as eg
from flax import linen as nn
class LSTMModel(nn.Module):
def setup(self):
self.embedding = nn.Embed(max_features, max_len)
lstm_layer = nn.scan(nn.OptimizedLSTMCell,
variable_broadcast="params",
split_rngs={"params": False},
in_axes=1,
out_axes=1,
length=max_len,
reverse=False)
self.lstm1 = lstm_layer()
self.dense1 = nn.Dense(256)
self.lstm2 = lstm_layer()
self.dense2 = nn.Dense(128)
self.lstm3 = lstm_layer()
self.dense3 = nn.Dense(64)
self.dense4 = nn.Dense(2)
@nn.remat
def __call__(self, x_batch):
x = self.embedding(x_batch)
carry, hidden = nn.OptimizedLSTMCell.initialize_carry(jax.random.PRNGKey(0), batch_dims=(len(x_batch),), size=128)
(carry, hidden), x = self.lstm1((carry, hidden), x)
x = self.dense1(x)
x = nn.relu(x)
carry, hidden = nn.OptimizedLSTMCell.initialize_carry(jax.random.PRNGKey(0), batch_dims=(len(x_batch),), size=64)
(carry, hidden), x = self.lstm2((carry, hidden), x)
x = self.dense2(x)
x = nn.relu(x)
carry, hidden = nn.OptimizedLSTMCell.initialize_carry(jax.random.PRNGKey(0), batch_dims=(len(x_batch),), size=32)
(carry, hidden), x = self.lstm3((carry, hidden), x)
x = self.dense3(x)
x = nn.relu(x)
x = self.dense4(x[:, -1])
return nn.log_softmax(x)Let's now create an Elegy model using the above network. As you can see, the loss and metrics are defined like in Keras. The model compilation is done in the constructor, so you don't have to do this manually.
import optax
model = eg.Model(
module=LSTMModel(),
loss=[
eg.losses.Crossentropy(),
eg.regularizers.L2(l=1e-4),
],
metrics=eg.metrics.Accuracy(),
optimizer=optax.adam(1e-3),
)Elegy model summary
Like in Keras, we can print the model's summary.
model.summary(jnp.array(X_train_padded[:64]))
Distributed training in Elegy
To train models in a distributed manner in Flax, we define parallel versions of our model training functions.
Read more: Distributed training with JAX & Flax
However, with Elegy, we call the distributed method.
model = model.distributed()Keras-like callbacks in Flax
Elegy supports callbacks similar to Keras callbacks. In this case, we train the model with the following callbacks:
- TensorBoard.
- Model checkpoint.
- Early stopping.
callbacks = [ eg.callbacks.TensorBoard("summaries"),
eg.callbacks.ModelCheckpoint("models/high-level", save_best_only=True),
eg.callbacks.EarlyStopping(monitor = 'val_loss',patience=10)
]
Read more: TensorBoard tutorial (Deep dive with examples and notebook)
Train Elegy models
Elegy provides the fit method for training models. The method supports the following data sources:
- Tensorflow Dataset.
- Pytorch DataLoader
- Elegy DataLoader, and
- Python Generators.
history = model.fit(
training_data,
epochs=100,
validation_data=(validation_data),
callbacks=callbacks,
)
Evaluate Elegy models
To evaluate Elegy models, use the evaluate function.
model.evaluate(validation_data)

Visualize Elegy model with TensorBoard
Since we applied the TensorBoard callback, we can view the performance of the model in TensorBoard.
%load_ext tensorboard
%tensorboard --logdir summaries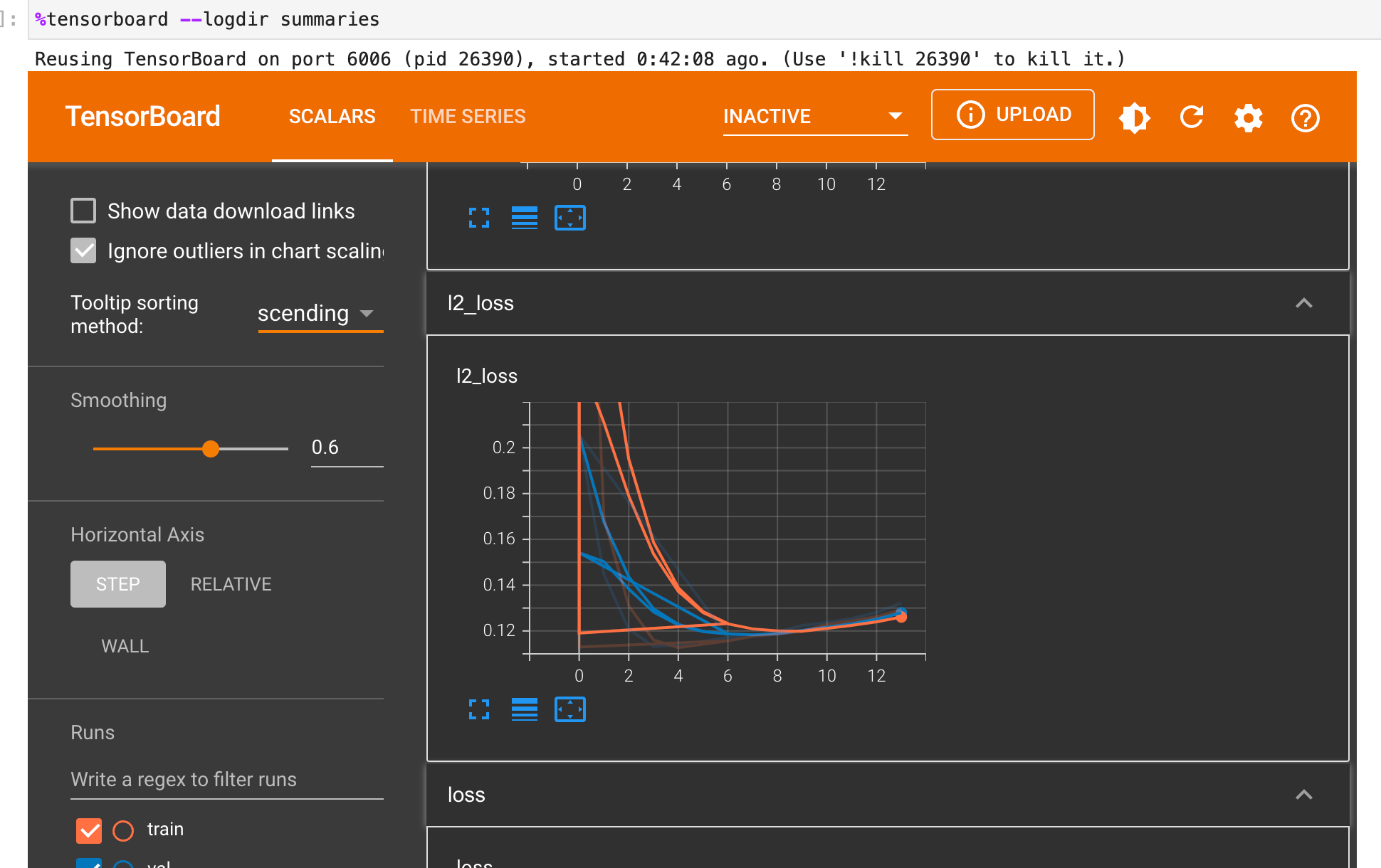
Read more: How to use TensorBoard in Flax
Plot model performance with Matplotlib
We can also plot the performance of the model using Matplotlib.
import matplotlib.pyplot as plt
def plot_history(history):
n_plots = len(history.history.keys()) // 2
plt.figure(figsize=(14, 24))
for i, key in enumerate(list(history.history.keys())[:n_plots]):
metric = history.history[key]
val_metric = history.history[f"val_{key}"]
plt.subplot(n_plots, 1, i + 1)
plt.plot(metric, label=f"Training {key}")
plt.plot(val_metric, label=f"Validation {key}")
plt.legend(loc="lower right")
plt.ylabel(key)
plt.title(f"Training and Validation {key}")
plt.show()
plot_history(history)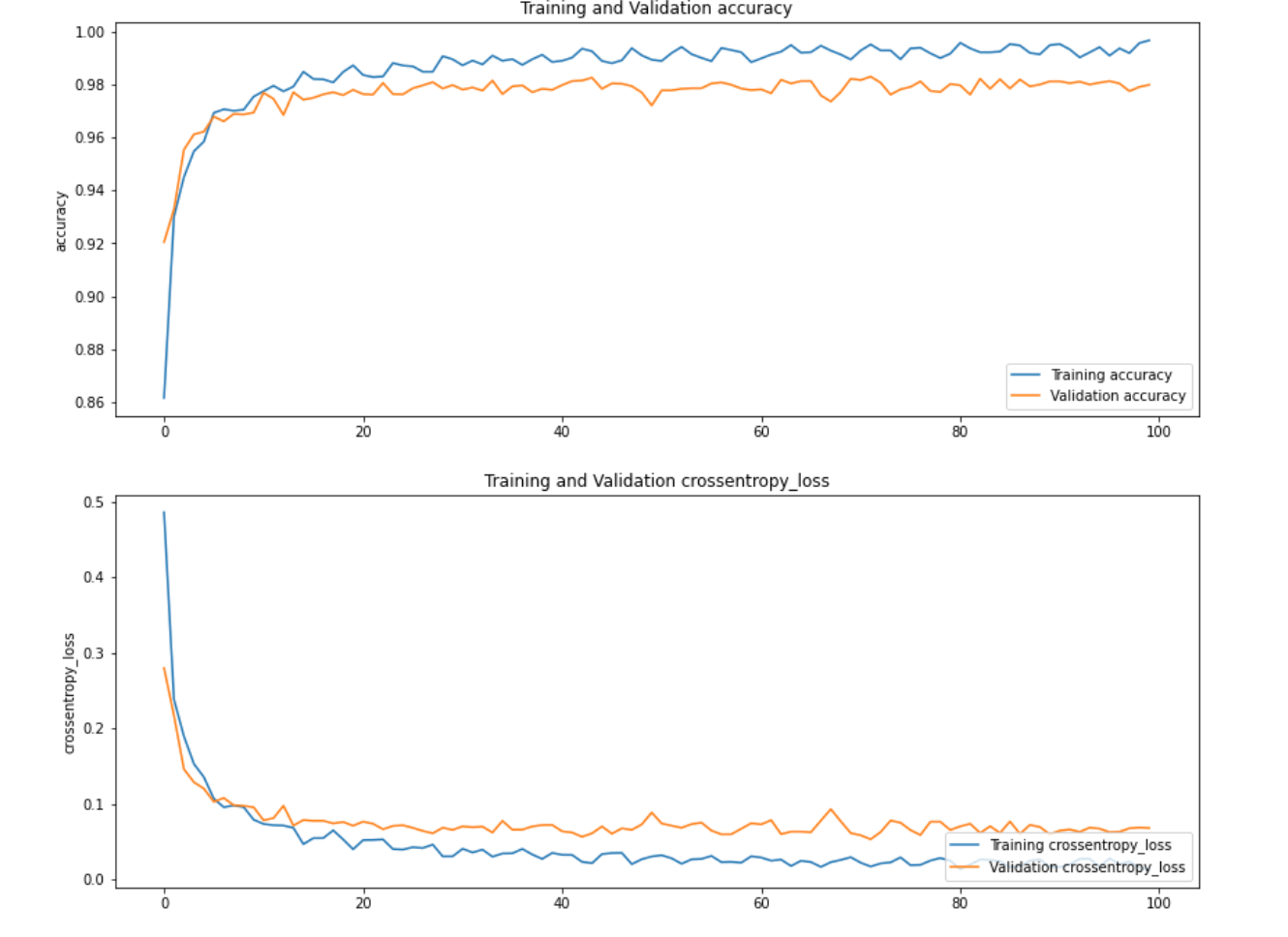
Making predictions with Elegy models
Like Keras, Elegy provides the predict method for making predictions.
(text, test_labels) = next(iter(validation_data))
y_pred = model.predict(jnp.array(text))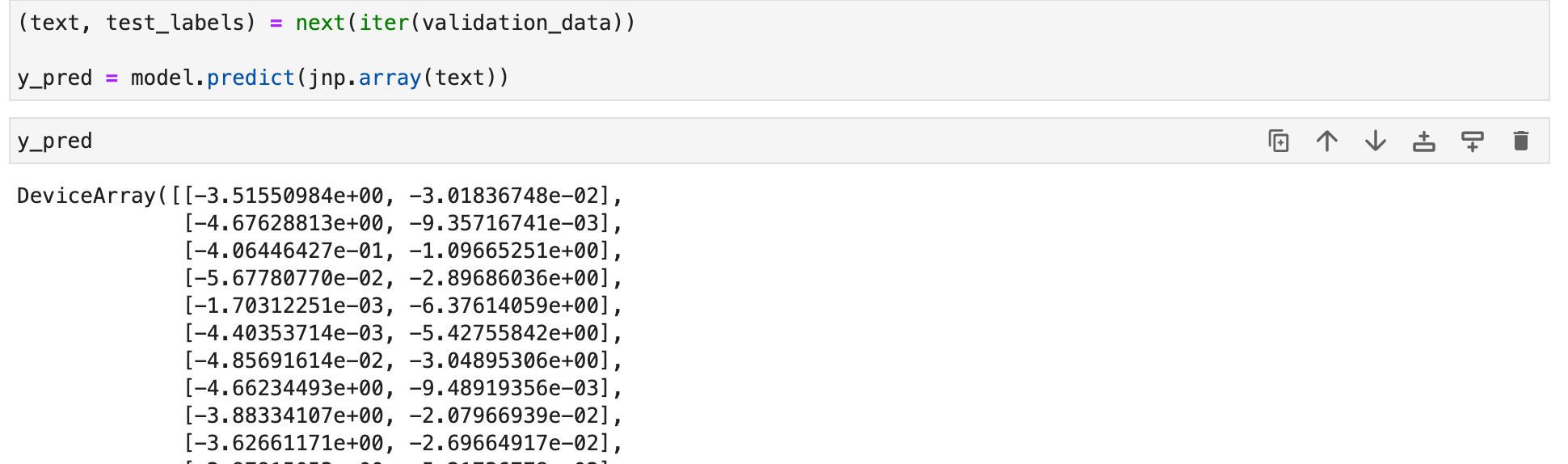
Saving and loading Elegy models
Elegy models can also be saved like Keras models and used to make predictions immediately.
# You can use can use `save` but `ModelCheckpoint already serialized the model
# model.save("model")
# current model reference
print("current model id:", id(model))
# load model from disk
model = eg.load("models/high-level")
# new model reference
print("new model id: ", id(model))
# check that it works!
model.evaluate(validation_data)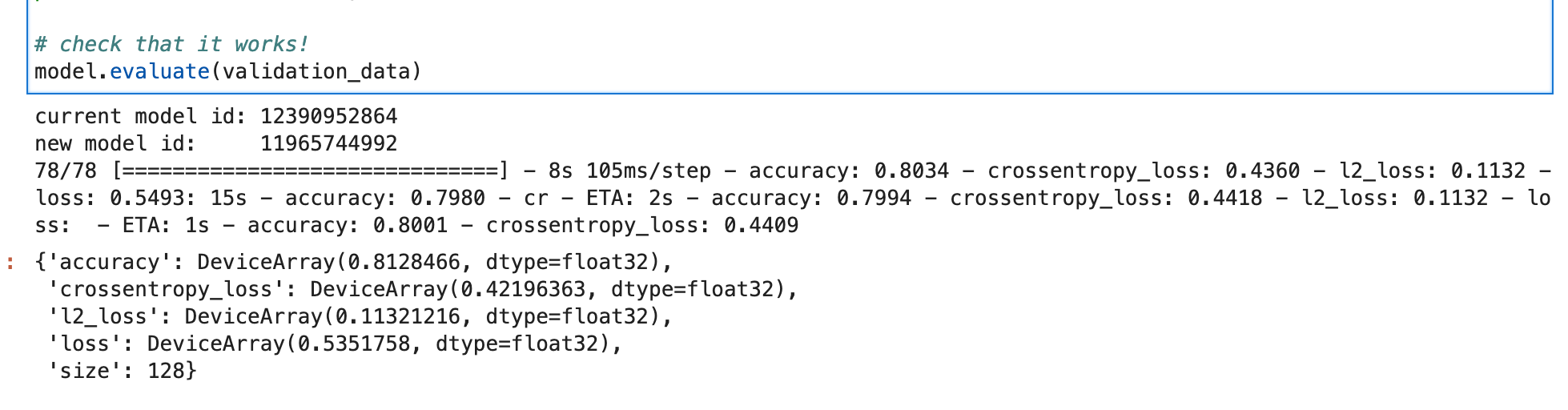
Final thoughts
This article has been a quick dive into Elegy– a JAX high-level API that you can use to build and train Flax networks. You have seen that Elegy is very similar to Keras and has a simple API for Flax. It also contains similar functions to Keras, like:
- Model training.
- Making predictions.
- Creating callbacks.
- Defining model loss and metrics.
JAX and Flax resources
- What is JAX?
- Flax vs. TensorFlow
- How to load datasets in JAX using TensorFlow.
- Building Convolutional Neural Networks in JAX and Flax.
- Distributed training in JAX.
- Jax loss functions.
- Using TensorBoard in JAX and Flax.
- LSTM in JAX & Flax.
- Optimizers in JAX and Flax
Follow us on LinkedIn, Twitter, GitHub, and subscribe to our blog, so you don't miss a new issue.